Customisable neural machine translation (NMT) is becoming increasingly accessible to freelance translators. In this article, translator, localisation engineer and translation technology developer Tommi Nieminen talks about the University of Helsinki’s OPUS project, his work in developing the OPUS-CAT software and how he sees translators interacting with and capitalising on NMT.
Tell us briefly about your background in translation and translation technology development and the path that led you to where you are now.
I did about four years as an in-house translator, during which time I learned how to translate and also learned the rudiments of translation technology.
Tommi Nieminen: I started in translation in 2000. I had a degree in philosophy, but you can’t get many jobs with that so I decided to change career. I got a job as a translator, even though I didn’t have an educational background in translation. I had studied in England, at the University of London, so I had the linguistic skills but no translation expertise. I basically learned on the job, spending about a year translating gaming magazines like PC Gamer. I was a freelancer for a while, but then I went back to England, to Sheffield, to work in-house for SDL. I later returned to Finland and worked for SDL there. I did about four years as an in-house translator, during which time I learned how to translate and also learned the rudiments of translation technology.
I then went back to freelancing and did that for quite some time. Meanwhile, I studied language technology on the side, part time, at the University of Helsinki, taking something like ten years to complete the degree. When Trados Studio and its API came out I started developing for that. I created the TermInjector plugin back then, which was relatively popular. I also started studying statistical machine translation and, on the basis of my private research, got a job at Lingsoft to build the first English-to-Finnish SMT system for professional use. My job was to set up the Moses system, but it didn’t work that well because morphology is so difficult for SMT. Then came the paradigm shift to neural machine translation and I quickly switched over to the Marian NMT Framework.
So basically, I’m a self-taught translator who studied language technology at the University of Helsinki, built stuff for Trados, got hired by Lingsoft then got involved in academia.
I then started working in academia, on Fiskmö (a research project funded by the Finnish/Swedish Cultural Association), using the Windows build of Marian NMT to create a local system and also creating the plugins for Trados and MemoQ. Later, Jörg Tiedemann at the University of Helsinki got a grant from the European Language Grid to further develop these tools and I got involved and completed OPUS-CAT.
So basically, I’m a self-taught translator who studied language technology at the University of Helsinki, built stuff for Trados, got hired by Lingsoft then got involved in academia. Everything happened pretty much by accident.
Could you tell us some more about the OPUS project at the University of Helsinki, the philosophy behind it and its aims?
T.N.: Jörg Tiedemann brought the OPUS project, which is basically a collection of parallel corpora, with him when he came to Helsinki. The idea is simple — collect everything available and host it in one place — but he was the first to think of it and the first to start doing it. It’s now essential to any kind of academic machine translation development.
What led you to develop OPUS-CAT within that context, and what is your ultimate vision for OPUS-CAT?
T.N.: Once you start working with Marian NMT you quickly notice that the CPU decoding speed is more than acceptable and that it runs well on desktops. That opens up the possibility of running a local MT system and it soon became clear that someone should make one. I first thought I’d build the models myself as well, but by the time I actually got the funding to start working on them within the Fiskmö project Jörg Tiedemann had already done it, which was a good thing because it’s a lot of work and you need a lot of GPU power, which Jörg Tiedemann had access to for academic use. Once those models were available, it was just a question of packaging the Marian decoder in Windows and creating the CAT tool connectors.
The problem with web interfaces is that it’s difficult to make them reliable enough and fast enough for real professional use.
You can run NMT through a web interface as well, but the problem with web interfaces is that it’s difficult to make them reliable enough and fast enough for real professional use. If you can run the system locally you don’t have to worry about an online MT service at all, which makes everything much simpler.
It’s something that became possible and I was in the right place to implement it. I did it basically because when I implemented Marian NMT at Lingsoft I discovered that while training the models is slow and resource-intensive, generating the translations is really quick. So, that was the motivation.
OPUS-CAT is intended to be a host for all kinds of features that I think might be useful for translators. The vision I have is of a kind of MT for power users so that people who are technically sophisticated can customise it for themselves and use all kinds of different capabilities.
From your perspective as both translator and developer, how do you see translators interacting with machine translation technology in general from here on, and where do you see MT providing them with greatest benefit?
T.N.: I’d personally like it to develop in the power user direction where you would have tons and tons of options for people to leverage MT. In the future, I’d like to see some kind of support for speech recognition added to machine translation. I think that’s going to be the big thing eventually. It would be a bit like Lilt, but with speech recognition, which would make it a lot more ergonomic to use. You would just tell the system to change a single word and it would potentially rework the whole structure of the sentence. For example, if a single word were incorrect in the MT output and you corrected that word, then it would modify the rest of the sentence to align it with that one correction. That would be the ultimate goal.
Just by making the n-best lists accessible to translators you could present a whole variety of structurally different machine translations.
I think there should be a dialogue between the translator and the system. For example, all MT systems produce n-best lists. Just by making the n-best lists accessible to translators you could present a whole variety of structurally different machine translations. I don’t know why only one option should be displayed to the translator.
Also, I’m not really happy with the way that all these web-based systems are becoming increasingly simplistic and, from the translator’s point of view, aren’t really adding any worthwhile features anymore, at least not when compared with desktop options. I’d like to start introducing more advanced methods of inputting translations.
Translation is getting caught in a crossfire right now. On the one hand, you’ve got project management innovation, which is pushing down prices, and on the other you’ve got technology innovation, like machine translation, which could be increasing productivity but isn’t really doing so because it’s simply being used to offload the work to cheaper vendors. There’s a drive from some stakeholders to make translation less of an expert field, even though if you want to make sophisticated use of translation technology then greater expertise is what’s needed.
That’s one of the great things about OPUS-CAT: it puts translators back in control as they gain all the benefits of working with customised machine translation without any of the downsides.
For translators not yet familiar with OPUS-CAT, what would you say are its greatest strengths, and how can we make the most of them?
If you’re sending work out to professional translators, then they should have the right to choose their own tools.
T.N.: The main thing is confidentiality. It’s universally usable on any job unless there’s a specific restriction on all machine translation. I know that some agencies have clauses banning all machine translation but I think those are pretty misguided in the sense that if you’re sending work out to professional translators, then they should have the right to choose their own tools, provided there’s no danger of any potential breach of confidentiality.
The second thing is, of course, the fine-tuning, because generic machine translation systems just aren’t good enough. The fine-tuning is the thing that makes it possible to use NMT in professional work. That said, the results of fine-tuning do vary quite a lot. Often just a few thousand relevant, good-quality segments will be enough to make a difference while even 100,000 segments aren’t likely to have much effect if they aren’t really relevant to the job at hand. It’s something to test, basically, to see if you get any advantage out of it, but the more relevant stuff you have, the better.
It’s a bit like black magic in a way and it’s very hard to predict what kind of effects fine-tuning will have. Occasionally it even degrades the output. That’s one thing, actually, about using MT in professional translation — you have to be aware of the limitations and pay close attention to the output you’re getting.
What feedback have you had from translators about OPUS-CAT? Are they asking for more features, or do you plan to add any new ones? If so, what’s in the pipeline?
T.N.: The feedback has generally been very positive. It’s a free product, so not many people are going to complain but, that said, the reception has been very, very positive. There’s a handful of very active users who provide a lot of feedback, and that’s been positive. Users have also indicated several problem areas, one of which was tagging. In response, I added tagging support to the Trados plugin, though it’s not yet available in the MemoQ plugin.
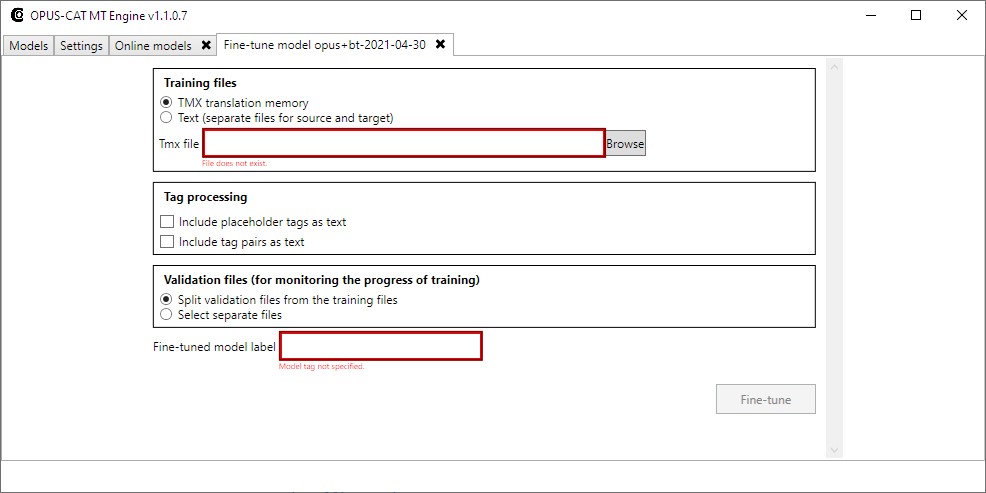
Fine-tuning can be another issue because people aren’t sure exactly what they should be fine-tuning and what the effects are.
Fine-tuning can be another issue because people aren’t sure exactly what they should be fine-tuning and what the effects are. It’s incredibly difficult to calibrate. I actually added it for my own use as I was working on a software translation job and the MT output wasn’t much use because all the terminology was incorrect. So, I added this fine-tuning feature to the plugin just for that job. And when I trained it and fine-tuned it — this was the kind of software translation job where you already have 10,000 translated strings — all the terms were suddenly correct and the output quality was really high. However, other users sometimes find that even after they fine-tune the engine the terms still don’t change, even though the correct terms are present in the fine-tuning material. It’s hard to pin down because there are so many factors at play.
Another thing people have been asking for is the option to use terminology lists directly. That’s one of the improvements I’m going to be working on this spring, drawing on the paper Tilde published on using factored translation in Marian NMT. I intend to add editable pre-editing and post-editing replacement rules to the system as well.
OPUS-CAT already allows users to download and install generic models from the OPUS repository and several models are now available. Are there plans for the OPUS project to continue generating new models as more datasets become available? If so, will it always focus on generic models or will there also be domain-specific ones?
The approach will probably be to produce generic models that can then be fine-tuned or, in the future, used in conjunction with term lists.
T.N.: The Tatoeba models are the ones that are being actively produced and they’re being added regularly. I’m pretty sure that’s going to continue, especially whenever new NMT techniques emerge. For instance, the initial models didn’t have guided alignment, which was added in the newer ones. They’re also working with more datasets as more texts become available, and those tend to percolate through, albeit with some delay. Using factored terminology will require new models as well, though those probably won’t be as good quality if you don’t use the terminology features with them. The models will be generic though because the data aren’t labelled by domain. That’s the main restriction. Also, the data tend to come from EU sources so they’re predominantly legal. The approach will probably be to produce generic models that can then be fine-tuned or, in the future, used in conjunction with term lists.
To close, what advice would you give translators keen to learn more about customisable NMT and how to make it work for them?
T.N.: I’d really just advise them to try it out and use it a lot, because gaining practical experience is pretty much the only way to learn about it. It’s just not possible to understand how it works. Rather, you should get a feel for how it affects different kinds of texts and see what the output is like after fine-tuning. If you’re feeling adventurous, you can change the fine-tuning parameters as well, though you would need to read up on things like training epochs, the learning rate, etc. You can test those parameters, but the problem is that there’s no logic to it, you just basically keep changing things until you no longer get the results you want. The OPUS-CAT default values are very conservative so they should work as intended, but that also means they might be too conservative for your particular use case. If you want to try things out, you can read the Marian NMT command line parameter descriptions and then change those parameters, but it’s going to take some time and, if you’re starting from zero it’s not going to be easy.
It’s a bit of a problem that the technology is still so unapproachable. It’s a mystery to everyone, including the researchers.
It’s a bit of a problem that the technology is still so unapproachable. It’s a mystery to everyone, including the researchers, and it’s really just a question of trial and error. Personally, I’ve seen that it works, but how often does it work and does it work universally? Those are the key questions.
In terms of more general advice, I would really like to see a shift towards greater technical sophistication among translators. I think people should strive to increase their technical skills in this field and then try to change the field to suit translators.
Links
OPUS-CAT [consulted on 21/02/22]
OPUS collection of parallel corpora [consulted on 21/02/22]
Marian NMT [consulted on 21/02/22]

Tommi Nieminen
Tommi Nieminen has worked as a translator, localisation engineer and translation technology developer for over twenty years. As a translator, he specialises in game and software localisation. Active in both academia and the localisation business, he has designed systems to automate translation workflows and leverage machine translation in professional settings. Since graduating with an MA in Language Technology from the University of Helsinki, he has contributed to several academic projects and has authored and co-authored multiple peer-reviewed articles on subjects related to machine translation. He regularly gives guest lectures on machine translation at Finnish universities and also teaches a course in software localisation at the University of Helsinki. Currently working as an independent translation consultant and translator, he also develops and maintains the OPUS-CAT project, which makes confidential and customisable state-of-the-art NMT available to translators free of charge.