Las herramientas de TAO más conocidas en general no ofrecen muchas prestaciones para la manipulación de las memorias de traducción, con lo que el traductor autónomo está a la merced de la buena o mala gestión que realice su jefe de proyectos, y el producto que este le envíe puede no ser su mejor aliado. En ocasiones, se echa en falta algo de autonomía. En este artículo se presenta un instrumento que cubre las carencias de otros programas —bien porque estos no dispongan de ningún módulo con un cometido similar, o bien porque, si lo tienen, este deje mucho que desear—, se citan sus funciones básicas y se exponen unos casos prácticos en los que se requieren estrategias avanzadas y que serán muy similares a los que se le presentan al traductor en su día a día. Olifant es un instrumento ideal por su flexibilidad, versatilidad y robustez.
Memorias y glosarios
Olifant es un programa que abre memorias de traducción exportadas por WordFast en formato txt o por las demás herramientas de TAO principales en formato tmx y les realiza una serie de transformaciones, entre ellas, eliminar segmentos (tecla Supr) y añadir otros insertando el contenido manualmente, editar el texto, de la lengua de origen o de la de destino, buscar y reemplazar, pasar el corrector ortográfico y eliminar las etiquetas. Todas estas operaciones se pueden realizar fácilmente nada más iniciarse en el programa y no precisan por lo tanto de explicaciones. En cambio, hay otros procesos que no son intuitivos, comprenden el uso de propiedades avanzadas o constan de varios pasos. Se detallan en el apartado «Casos prácticos».
Una propiedad interesante es que todo lo que se haga con una memoria se puede hacer igualmente con un glosario. Basta con importarlo como archivo delimitado por tabulador. A partir de ahí, el programa no distingue entre un tipo u otro de base de datos, sino que los presenta a ambos en la misma interfaz y permite realizarles las mismas operaciones.
Nota terminológica: en este artículo se utiliza el término base de datos como sinónimo de memoria y, para el caso, también es intercambiable con glosario. Por otra parte, se utilizan como sinónimos absolutos segmento, entrada, unidad y unidad de traducción.
Proyectos de código abierto
Olifant forma parte del proyecto Okapi Framework, un conjunto de aplicaciones gratuitas y de código abierto para traductores y localizadores que sirven para realizar tareas como el control de calidad, la pretraducción y la aplicación de reglas de segmentación. Existe una lista de distribución dedicada a la colección.
Resulta un complemento perfecto para quienes trabajen con OmegaT, otro programa de código abierto.
Nota sobre la información disponible en Internet: actualmente (mediados de 2012), el proyecto Okapi Framework está alojado en dos sitios web independientes, ya enlazados en este artículo, correspondientes a dos versiones distintas del software. Olifant solo aparece en el primero de ellos, aunque será conveniente vigilar el más moderno para detectar las novedades que haya.
Instalación
Una vez descargado, es necesario bajarse también la aplicación .NET Framework 2.0 e instalarla antes que el programa. Contrariamente a lo que se afirma en el sitio de Okapi Tools, mi experiencia ha demostrado que no (siempre) se puede instalar Olifant con una versión de .NET superior a la mencionada, por lo que si tu ordenador ya dispone de una más moderna, tendrás que buscar la antigua e instalarla también. En ocasiones, ocurre incluso que no puede instalarse la versión 2.0 si ya hay una más avanzada, con lo que habrá que proceder a desinstalar, limpiar el registro y volver a instalar ambas en orden ascendente. Cada uno de estos pasos, de por sí, ya es bastante lento. Recomiendo concienciarse, destinar una sustanciosa entrada de la agenda a la instalación y tener paciencia.
Trampas
- La función de buscar no explora unidades de traducción anteriores a aquella en que nos encontremos, es decir, no explora el texto hacia atrás. Puede ser engañoso, por tanto, un mensaje que informe de que la palabra buscada no se ha encontrado.
- En ocasiones, se observará que los últimos cambios efectuados no se deshacen con el archiconocido atajo Ctrl+Z. La incidencia puede tornarse desesperante al constatar que tampoco funciona la opción equivalente de deshacer del menú de edición, sobre todo si lo que acabamos de hacer es borrar segmentos que nos son útiles. La explicación está en que Olifant distingue entre dos funciones parecidas pero no iguales: una, «deshacer la última modificación» (undo last edit), que se aplica a los cambios realizados en el texto propiamente dicho; y otra, «deshacer los últimos cambios de la tabla» (en el mismo menú), para operaciones que afectan a la estructura de la base de datos, como destacar o borrar segmentos o conmutar entradas del texto de destino.
Casos prácticos
Si bien la página del proyecto ya contiene varios tutoriales, considero que es útil leer con detenimiento los problemas presentados en este opúsculo aunque no versen sobre situaciones idénticas a las que se le presenten al lector (de hecho, en ocasiones los ejemplos son forzados; en el supuesto 2, por ejemplo, debería ser responsabilidad del cliente proporcionar una memoria adecuada). En este apartado se exponen las funciones más importantes de Olifant, y los recursos tratados con toda probabilidad podrán combinarse unos con otros y servirán para confeccionar las estrategias encaminadas a abordar una infinidad de situaciones complejas. Sin más, paso a presentar los supuestos, con esquema de consultorio sentimental e ilustraciones a modo de híbrido entre cómic y manual de Ikea.
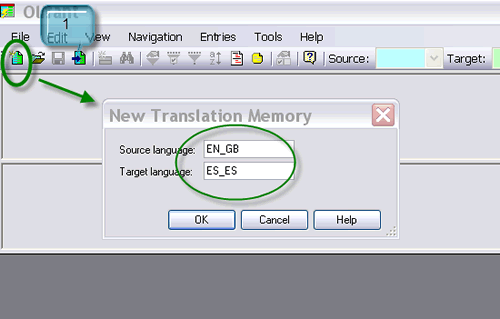
Supuesto 1: Tengo una memoria de traducción en formato tmx y quiero cambiarle los idiomas que tiene asignados como origen y destino, de inglés de Irlanda a inglés de Gran Bretaña y de español de Colombia a español de España. La he abierto con los procesadores de textos convencionales y los problemas con los que me topo son que las etiquetas no son editables (en el caso de Word) o que el programa no tiene la opción de buscar y reemplazar en bloque (Notepad).
JavierH: En primer lugar, he de decir que para no matar moscas a cañonazos se puede reemplazar en bloque con OpenOffice o con Notepad++. Esta última es una sencilla herramienta pensada en realidad para programadores, pero de instalación tan inmediata que merece la pena descargarla tan solo para este propósito. Para quienes vayan a recurrir a Olifant y examinar las siguientes imágenes, señalo simplemente que es importante no confundir la función de crear una nueva memoria con la de importar. De paso, comento que la segunda sirve para agregar a la memoria que tengamos abierta los segmentos de otra o, lo que es lo mismo, fundirlas.
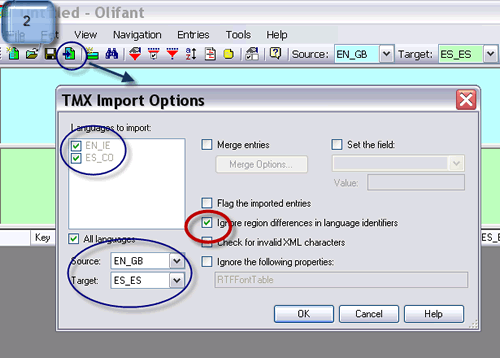
S2: Mi cliente me envía una memoria actualizada para un trabajo de seguimiento y me pide que utilice esta versión puesto que se le ha añadido una serie de segmentos importantes. En circunstancias normales, me limitaría a utilizar la memoria más reciente y prescindir de la anterior, pero se da la circunstancia de que invertí un gran esfuerzo en modificar la que produje en la fase previa conforme a la terminología y el estilo que prefiere el usuario final. Observo que la base de datos que acabo de recibir no atiende a estas preferencias y concluyo que su única ventaja respecto a la mía es su mayor número de unidades. Lo ideal sería contar con un procedimiento que las fundiera y conservara lo mejor de cada una. ¿Qué aporta Olifant ante esta coyuntura?
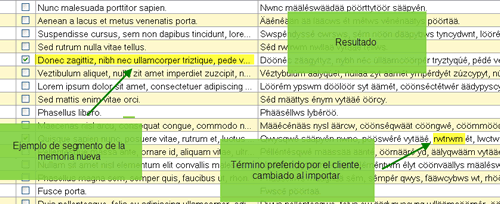
JH: La función que nos sacará del atolladero en este caso es la de sobrescribir. Será preciso abrir con Olifant en primer lugar la memoria nueva, y a continuación importar la antigua del modo que indican las imágenes. Los segmentos cuyo campo en inglés esté duplicado adoptarán en español la versión de la memoria antigua —la segunda que abramos—, mientras que los segmentos que aparezcan una sola vez, es decir, los que no estuvieran en la base de datos previa, quedarán intactos.
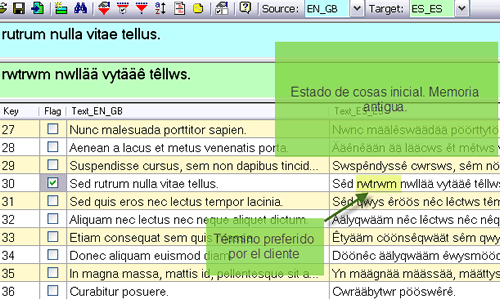
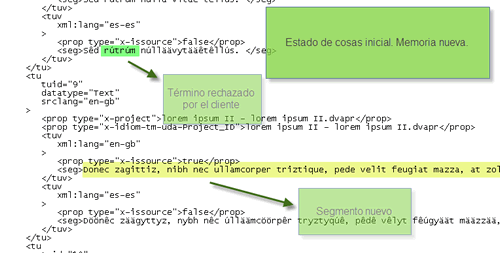
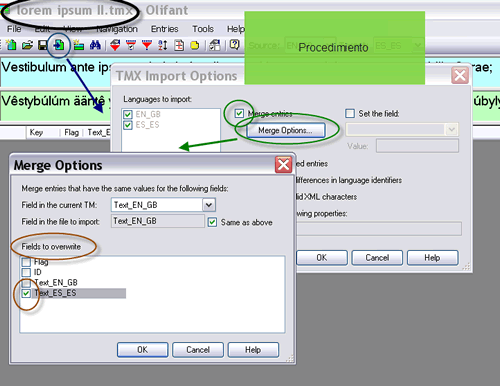
S3: Mi caso es parecido al anterior, pero no quiero verme encorsetado por este procedimiento, según el cual tendré que aceptar ciertos segmentos de traducción en función de la memoria en que se encuentren. Necesito libertad para cotejar las dos versiones de algunas de las unidades de traducción —o de todas—, eliminar la que no me convenza y editar la otra a conciencia según mis preferencias.
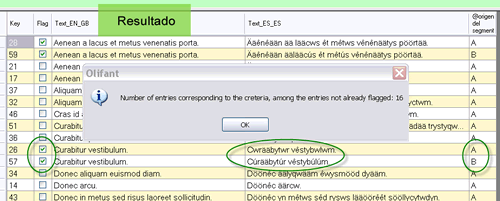
JH: Entonces, habrá que crear una memoria en blanco en la que fundiremos las dos con las que trabajamos, a continuación destacaremos (en inglés, flag) las unidades de traducción cuyo campo original aparezca en ambas memorias (el programa las llamará duplicadas), para poder identificarlas fácilmente, y por último mostraremos cada segmento junto con su homólogo para ir contrastando todos los pares con detenimiento. Convendrá marcar ambas memorias durante la importación creando un tercer campo que indique a cuál de ellas pertenece cada entrada. Por último, utilizaremos los filtros para ver solo los segmentos destacados. Lo que no deberemos hacer esta vez es sobrescribir.
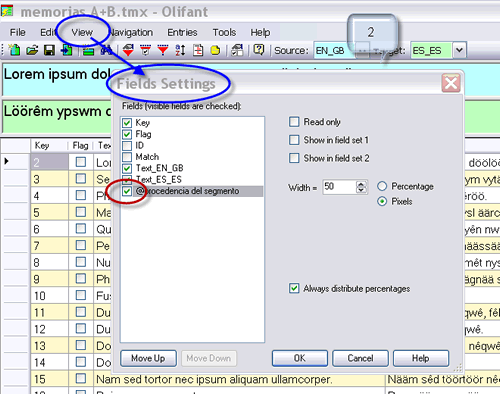
El paso 2 es necesario porque Olifant no muestra de forma predeterminada los campos adicionales que creamos.
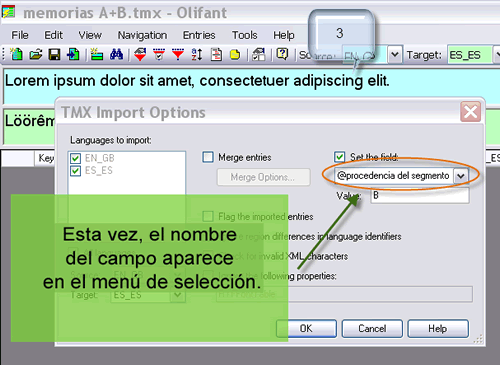
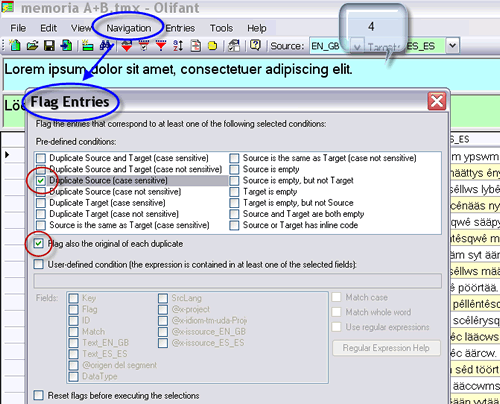
Con este último paso, las entradas se muestran automáticamente por orden alfabético.
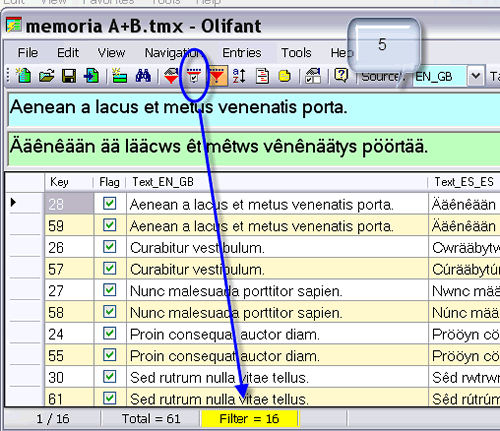
Lo que hemos hecho ha sido recurrir al filtro para que nos muestre solo las unidades que nos interesan (las que habíamos destacado anteriormente). De lo contrario, habrá que avanzar con la barra de desplazamiento por todo el texto para ir localizando las que tengan la casilla marcada.
S4: Mi cliente me envía una memoria actualizada. No tengo constancia de cuáles son los cambios que ha realizado, simplemente sé que ha efectuado correcciones. Quiero tomar conciencia de las más recurrentes para utilizar la terminología y el estilo de forma homogénea, incluyendo también los segmentos sin coincidencias, pero temo que la solución sea estar esclavizado por el botón de concordancia e ir comprobando término por término si el cliente ha aceptado el léxico que yo venía usando. Se me ocurre utilizar la función de comparar y combinar documentos de Word, pero como hay demasiadas unidades que están en la memoria antigua pero no en la nueva, y viceversa, el texto queda como un campo de batalla y su inspección esmerada resulta ardua. ¿Ofrece Olifant alguna prestación que dé los mismos resultados pero sea menos farragosa?
JH: No, pero en algo nos facilitará la vida: contamos con un par de artimañas para deshacernos de los segmentos que nos supongan ruido informativo y producir dos tablas de Word con sendas memorias por separado.
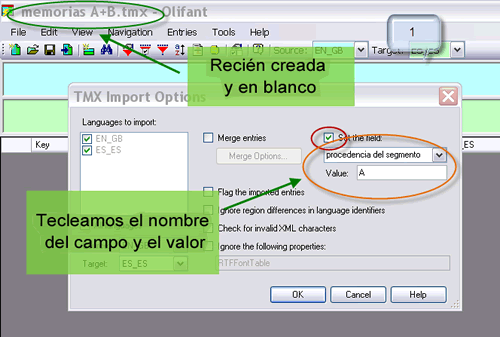
Volvemos al supuesto de la memoria A+B, que contiene las dos bases de datos con las que trabajamos. Repetimos todos los pasos anteriores y, una vez que tengamos filtradas las entradas duplicadas, ordenamos alfabéticamente por el campo «procedencia del segmento» (basta con hacer clic en el nombre del campo). Entonces quedarán todos los segmentos de la memoria A al principio y los de la B al final. Por último, habrá que exportar la memoria A+B como archivo de WordFast, aunque no dispongamos de este programa. Es el único formato manejable y permite una fácil conversión a tabla con un procesador de textos convencional para dividir posteriormente el texto en dos. Puesto que estamos aplicando el filtro, se procesarán únicamente los segmentos que se muestren en el momento de la exportación. Ya solo nos falta comparar los archivos resultantes.

Javier Herrera
Se licenció en Traducción e Interpretación en la Universidad de Granada en 2001 y empezó a ejercer la profesión poco después. Traduce textos científico-técnicos y tiene un interés particular por la tecnología aplicada a la traducción. Se ocupa de la SEO (Search Engine Optimization) de La Linterna, una disciplina encaminada a dar la máxima visibilidad posible a los sitios web y, desde el número 17, es también ayudante de dirección.