
Okapi ofrece una gran cantidad de herramientas, y en este tercer artículo dedicado a ellas presentamos Checkmate, Ocelot, Ratel, los filtros adicionales para OmegaT y Longhorn. Actúan como complementos a las presentadas en los artículos previos: Tikal y Rainbow. Okapi nos va a ofrecer una solución para la mayoría de las situaciones en las que nos podemos encontrar cuando creamos y procesamos nuestros proyectos de traducción.
1. Introducción
En esta tercera y última entrega de la serie de artículos dedicados a Okapi vamos a presentar el resto de las herramientas que ofrece este sistema: Checkmate, Ocelot, Ratel, los filtros adicionales para OmegaT y Longhorn. Les dedicaremos más atención a las primeras herramientas mencionadas y menos a las últimas, por ser estas de carácter mucho más especializado.
2. Checkmate
Checkmate permite realizar diversas verificaciones y controles de calidad a archivos bilingües.
Esta herramienta permite realizar diversas verificaciones y controles de calidad a archivos bilingües. Los formatos que admite son los formatos de archivos bilingües que procesa Okapi, como por ejemplo XLIFF, PO, TMX, etc. La lista de elementos que permite verificar es muy larga e incluye una corrección ortográfica y gramatical mediante la herramienta LanguageTool. Vamos a ver algunas de sus características mediante un ejemplo de uso.
Disponemos de una memoria de traducción proporcionada por un cliente, pero antes de empezar a utilizarla en nuestros proyectos queremos estar seguros de que ofrece la calidad suficiente. Para ello, simplemente tenemos que abrir la memoria de traducción en Checkmate y hacer clic en el botón Check all o en Check document. Nos aparecerá una pantalla como la siguiente:
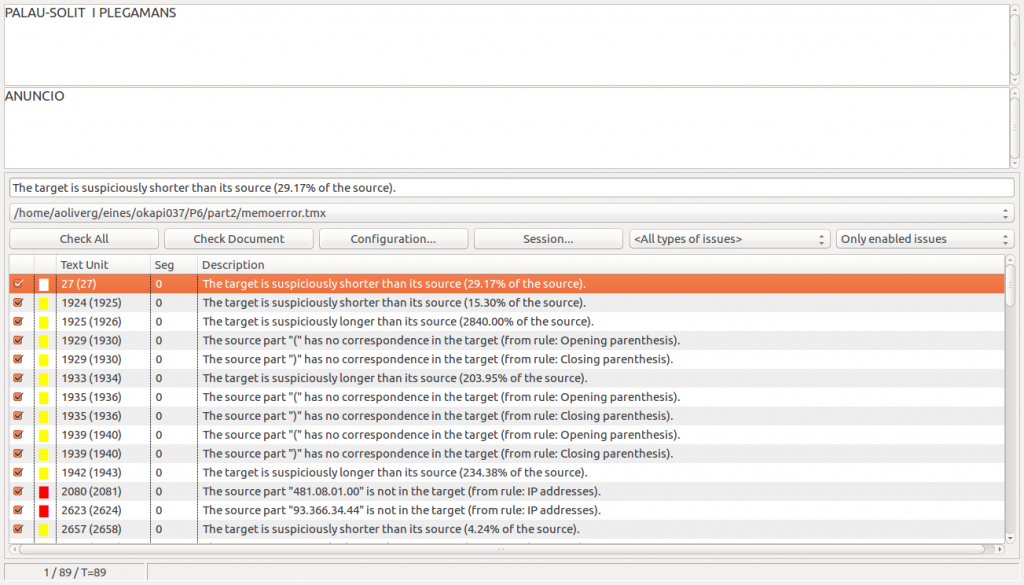
La pantalla nos muestra un segmento de traducción y una lista de errores encontrados en el archivo. Como no hemos realizado ninguna configuración, nos ofrecerá los errores definidos por defecto. Para configurar el tipo de errores que deben detectarse, simplemente tenemos que ir a Issues > Edit configuration y nos aparecerá una ventana con diversas pestañas para los distintos tipos:
- General: para errores como palabras repetidas o entradas que carecen de traducción.
- Length: donde podemos configurar las advertencias por segmentos demasiado largos o demasiado cortos.
- InLine Codes: para configurar las verificaciones de etiquetas.
- Patterns: donde se puede definir una serie de expresiones regulares que identifiquen elementos del texto de partida y establezcan la forma en que estos deben traducirse. Por ejemplo, podemos detectar las direcciones de correo electrónico y exigir que estas aparezcan también en la traducción.
- Character: que permite la detección de caracteres mal codificados o limita los caracteres que pueden aparecer a los propios de una determinada codificación.
- LanguageTool: donde podemos configurar el corrector ortográfico y gramatical.
- Terms: para definir la verificación de la coherencia terminológica aportando una base de datos terminológica en formato TBX.
- Other Settings: donde, además de especificar otras verificaciones, podemos también guardar la configuración actual para utilizarla más adelante.
Hay que tener en cuenta, no obstante, que Checkmate es un verificador, no un editor.
Configurando convenientemente la herramienta, podremos realizar verificaciones complejas y asegurarnos de que nuestra memoria de traducción sea realmente correcta. Hay que tener en cuenta, no obstante, que Checkmate es un verificador, no un editor. En Checkmate podremos detectar los errores, pero no corregirlos. Para ello, tendremos que tener abierto el archivo en algún editor y corregir los errores en él. Una vez corregido el error, para visualizar la verificación actualizada, tendremos que hacer clic en el botón Check All o en Check Document. Para ahorrarnos este paso, podemos ir a File > Session Settings y marcar la opción Re-check documents automatically when they change.
Otra opción muy útil es la posibilidad de generar automáticamente un informe con los errores encontrados yendo a Issue > Generate Report. Si hemos realizado un encargo a un colaborador y nos ha devuelto su trabajo en formato XLIFF, por ejemplo, podemos realizar las verificaciones y, si encontramos errores, enviarle el informe pidiéndole que los corrija.
2. Ocelot
Ocelot es un editor de archivos XLIFF que se puede utilizar para realizar la traducción y que ofrece también funcionalidades avanzadas para revisar y corregir traducciones.
Ocelot es un editor de archivos XLIFF que se puede utilizar para realizar la traducción y que ofrece también funcionalidades avanzadas para revisar y corregir traducciones. Vamos a ver estas dos posibilidades de uso proponiendo dos situaciones habituales.
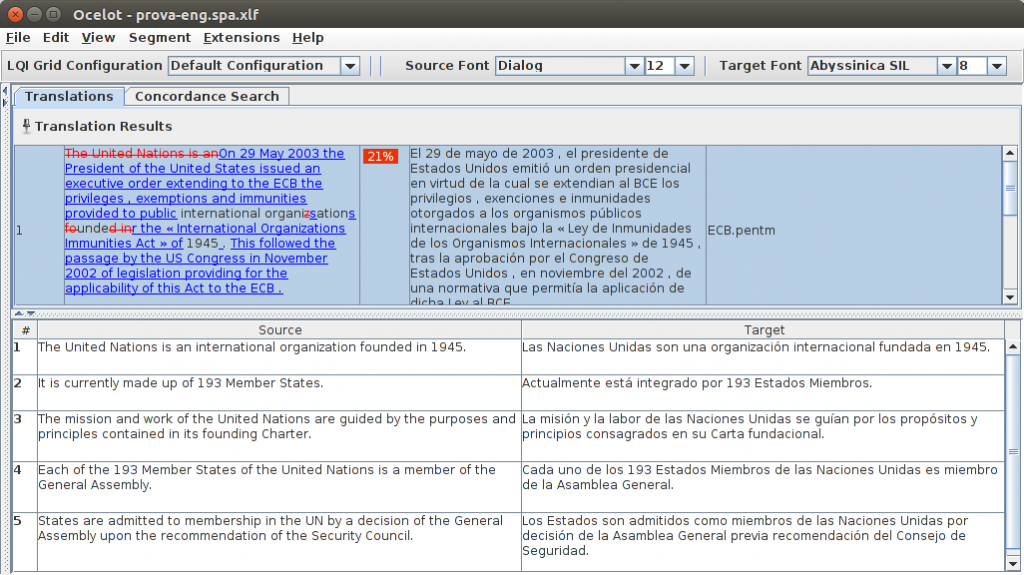
Queremos colaborar con un traductor que no dispone de ninguna herramienta de traducción asistida y que es muy reticente a aprender a utilizar aplicaciones complejas. En nuestro flujo de trabajo trabajamos con formatos estándar, y los proyectos de traducción los generamos en formato XLIFF. Además, queremos que utilice una memoria de traducción que está en formato TMX. En este caso, Ocelot es la solución, ya que permite abrir el XLIFF y seleccionar la memoria TMX para utilizarla en el proyecto. Hay que tener en cuenta que Ocelot permite una configuración muy detallada de la información que aparecerá en pantalla. En esta situación, podemos mostrar simplemente las columnas source y target y ocultar la sección de categorización de errores. La herramienta en esta situación tendría el siguiente aspecto:
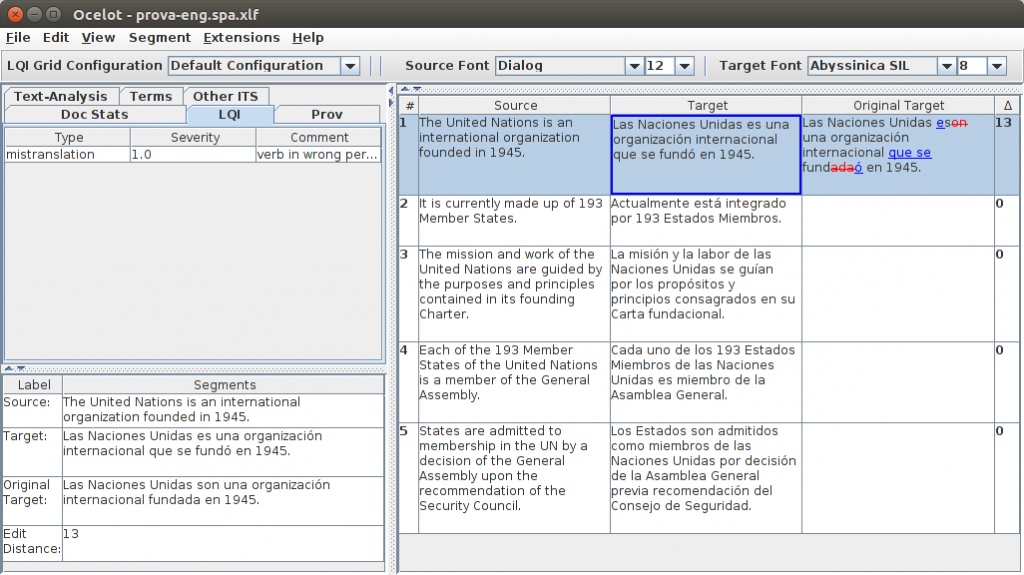
Pero, como ya hemos comentado, Ocelot es mucho más que un simple editor de archivos XLIFF y se puede convertir en un complejo entorno de revisión de traducciones. Imaginemos la siguiente situación: nos estamos planteando empezar a utilizar un sistema de traducción automática, pero antes queremos realizar una evaluación exhaustiva y una clasificación de los errores que este comete. En este caso, podemos utilizar Ocelot con una visualización que nos permita ver el original, la traducción posteditada, la traducción original y la distancia de edición. Además, hemos activado la pantalla que nos permite marcar y categorizar los errores. Podemos ver esta configuración en la siguiente figura:
3. Ratel
Ratel es una herramienta que permite editar y probar reglas de segmentación.
Ratel es una herramienta que permite editar y probar reglas de segmentación. Estas reglas se utilizan para dividir los textos que vamos a traducir en segmentos, es decir, en unidades que en muchos casos coinciden con oraciones. Las herramientas de traducción asistida utilizan estas reglas para dividir el texto y presentar al traductor el texto segmentado. Además, las herramientas TAO utilizarán estas unidades para realizar búsquedas en las memorias de traducción. En general, los sistemas TAO disponen de reglas de segmentación adecuadas para la mayoría de las lenguas y tipos de texto y, por lo tanto, no es demasiado habitual encontrarse en la necesidad de modificarlas. En este sentido, Ratel no será una herramienta de uso imprescindible para la mayoría de los traductores. No obstante, en algunos casos muy concretos, sí conviene modificar estas reglas: textos con expresiones numéricas complejas y unidades o símbolos que hacen que las reglas estándar fallen. En estos casos, al importar nuestro documento en la herramienta TAO, nos encontraremos con segmentos sin sentido que harán muy difícil la traducción del documento.
Existe un formato estándar basado en XML para el intercambio de reglas de segmentación: el SRX (Segmentation Rules eXchange). Ratel puede trabajar directamente con este formato, de manera que las reglas que creemos o modifiquemos se podrán utilizar directamente en muchas herramientas de traducción asistida.
El formato SRX es muy útil; por ejemplo, en los casos en que queramos compartir una memoria de traducción con algún colaborador que vaya a crear el proyecto de traducción con su propia herramienta. Si utiliza las mismas reglas de segmentación que se utilizaron en los proyectos que han dado lugar a las memorias de traducción, la probabilidad de encontrar segmentos coincidentes aumentará.
Las reglas de segmentación se expresan mediante expresiones regulares. Ratel nos permite añadir reglas de segmentación mediante una interfaz muy sencilla:
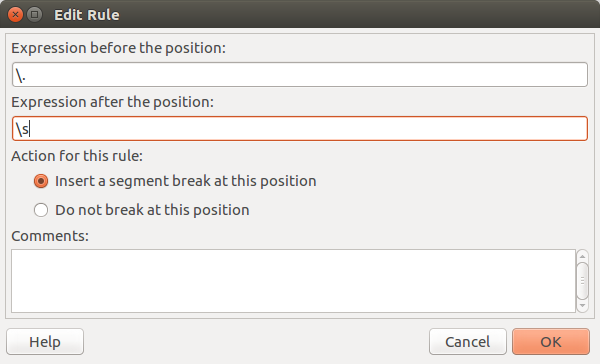
Simplemente, tenemos que poner la expresión regular que define la cadena justo antes del punto de salto o no salto de segmento (en el ejemplo, la expresión sería un punto), la expresión regular que define la cadena justo después del punto de salto o no salto e indicar si el punto definido de esta manera es un salto de segmento o no.
Una vez añadida la regla, podemos verificar cómo funciona con una frase de ejemplo en la interfaz de Ratel:
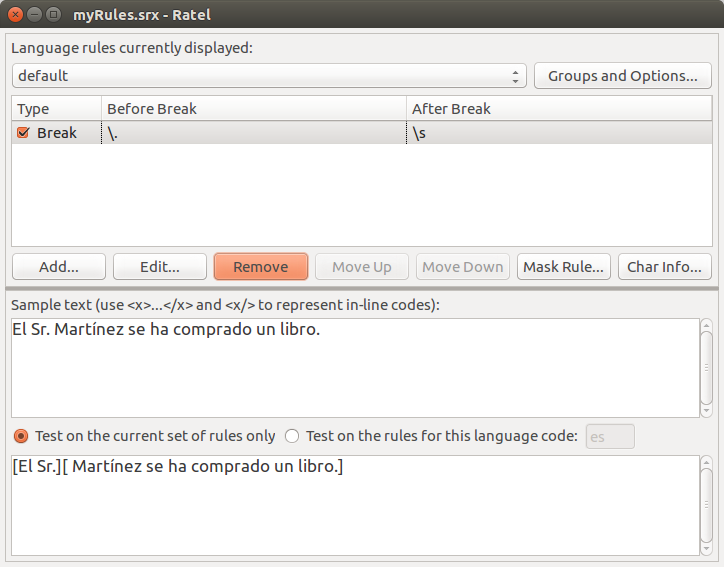
Como podemos observar, la regla no funciona demasiado bien porque segmenta después de la abreviatura «Sr.». Podemos indicar ahora una regla de no saltar de segmento:
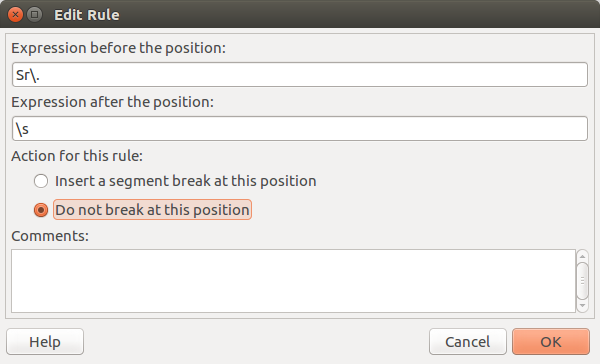
Y verificar si ahora funciona mejor con la misma frase:
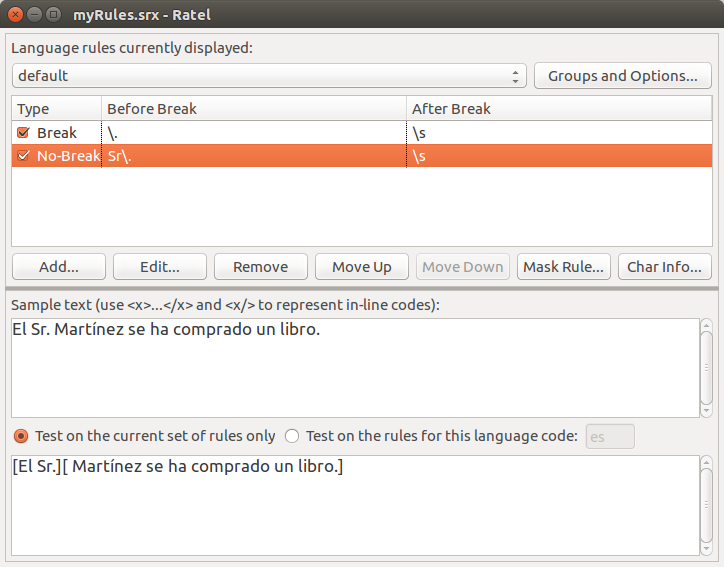
¿Cómo puede ser que todavía no funcione? Las reglas de segmentación dependen del orden y, si la primera regla indica que hay un salto, esta acción no se puede deshacer después. La definición correcta de las reglas tiene que indicar que la regla de no saltar va antes, cosa que podemos conseguir utilizando el botón Move up. Veamos el resultado:
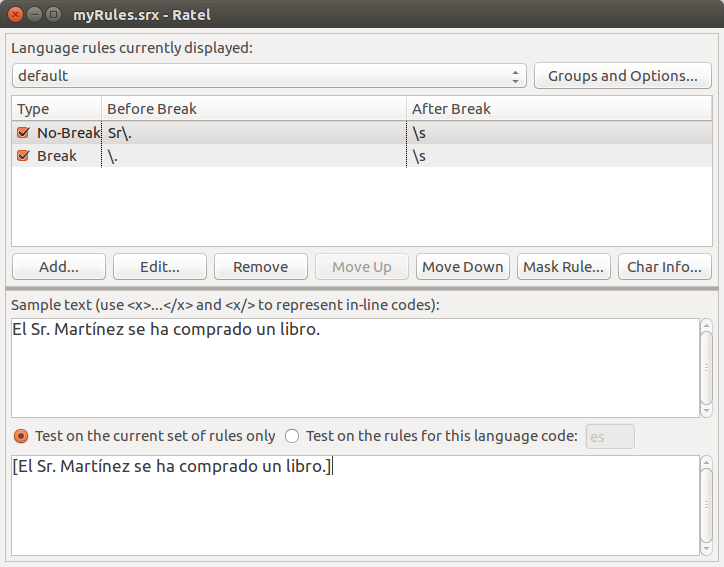
Y vemos que ahora funciona correctamente.
4. Filtros adicionales para OmegaT
OmegaT es una herramienta de traducción asistida libre muy completa y popular entre los traductores.
OmegaT es una herramienta de traducción asistida libre muy completa y popular entre los traductores. Ofrece filtros para numerosos formatos de entrada, y el proyecto Okapi ofrece unos filtros adicionales para esta herramienta. Estos filtros adicionales se distribuyen como plugins en formato JAR, y para instalarlos simplemente se tiene que copiar el archivo JAR en el directorio «Plugins» de OmegaT y reiniciar el programa. A partir de este momento, OmegaT podrá procesar más formatos, como, por ejemplo, archivos Doxygen, InDesign IDML, JSON o Yaml, entre otros.
5. Longhorn
Longhorn es una aplicación pensada para usuarios avanzados, gestores de proyectos y administradores de sistemas.
Longhorn es una aplicación de tipo servidor que permite ejecutar pipelines exportados de Rainbow de manera remota. Con ello, podemos configurar un servicio web que permita realizar las mismas operaciones que podemos definir con Rainbow. Por ejemplo, podemos realizar una aplicación que de manera remota convierta un archivo de Open Office a XLIFF y lo pretraduzca con una determinada memoria de traducción y con un sistema de traducción automática. Podría servir como aplicación para preparar proyectos de traducción de manera remota. Es una aplicación pensada para usuarios avanzados, gestores de proyectos y administradores de sistemas.
6. Conclusiones
En esta tercera y última entrega de artículos dedicados a las herramientas de Okapi hemos presentado las cinco aplicaciones que nos faltaban. Las hemos ordenado tomando como criterio la probabilidad de que un traductor con necesidades tecnológicas medias las utilice.
En esta serie de artículos hemos podido comprobar la gran potencia del conjunto de herramientas de Okapi, que nos permiten realizar una cantidad prácticamente ilimitada de operaciones a nuestros archivos. Ahora solo toca que el lector se anime a probarlas sin miedo y que cuando se encuentre con una necesidad concreta recuerde que estas herramientas seguramente le proporcionarán la solución.

Antoni Oliver
Antoni Oliver es profesor agregado de los Estudios de Artes y Humanidades de la Universitat Oberta de Catalunya (UOC, Barcelona, España) y director del Máster en Traducción y Tecnologías. De formación es ingeniero técnico de Telecomunicaciones (UPC), licenciado en Filología Eslava (UB), máster universitario en Software Libre (UOC) y doctor en Lingüística (UB). Sus áreas de docencia e investigación principales son el procesamiento del lenguaje natural, la traducción automática y las herramientas de ayuda a la traducción. Ha participado en diversos proyectos de investigación y transferencia de tecnología y actualmente es el investigador principal del proyecto Traducción automática neuronal para las lenguas románicas de la península ibérica (TAN-IBE). Ha desarrollado numerosas herramientas libres relacionadas con la traducción automática (entre las que destaca el proyecto MTUOC) y la extracción automática de terminología (recogidas en el proyecto TBXTools). Es autor de numerosos artículos en revistas científicas y del libro Herramientas tecnológicas para traductores.
