En esta entrevista con La Linterna del Traductor, Antoni Oliver, investigador y docente de la Universitat Oberta de Catalunya (UOC), nos habla de MTUOC, un proyecto que tiene como principal objetivo facilitar el entrenamiento, el uso y la integración de sistemas de traducción automática neuronal por medio de herramientas y programas distribuidos bajo una licencia libre (GNU GPL v3).
¿Puedes contarnos un poco sobre tu trayectoria dentro del mundo de la traducción y del desarrollo de las tecnologías asociadas con la traducción asistida y de cómo llegaste a tu situación actual?
Para optimizar mi trabajo de traductor, empecé a utilizar herramientas de traducción asistida, lo que renovó mi interés por las tecnologías del lenguaje y la traducción.
Antoni Oliver: Desde joven me han interesado mucho las lenguas, pero también la ciencia y las tecnologías. A la hora de escoger estudios universitarios, dudaba entre hacer una ingeniería o bien alguna carrera relacionada con la lingüística. Finalmente me decidí por hacer una ingeniería, pero al acabar mis estudios mi interés por las lenguas continuaba, por lo que decidí empezar una filología, concretamente Filología Eslava. Durante estos estudios de filología tuve la oportunidad de cursar asignaturas relacionadas con el procesamiento del lenguaje natural, lo que encajaba muy bien con mis estudios previos de ingeniería. Finalizados mis estudios de Filología Eslava, vi que una buena salida era la traducción, que quería compaginar con mi trabajo de ingeniero y de docente en educación secundaria. Contacté con diversas agencias de traducción para ofrecerme como traductor del ruso y croata al español o catalán. Pero las agencias, al ver mi currículum, me empezaron a enviar trabajos de traducción técnica del inglés al español y no pude traducir prácticamente nada del ruso o croata. Para optimizar mi trabajo de traductor, empecé a utilizar herramientas de traducción asistida, lo que renovó mi interés por las tecnologías del lenguaje y la traducción. Esto me llevó a decidirme a iniciar mis estudios de doctorado en lingüística computacional, donde realicé una tesis sobre el aprendizaje automático de la morfología aplicada al ruso y al croata. Finalizado mi doctorado, empecé a trabajar en proyectos de investigación y en docencia en diversas universidades, hasta que conseguí la plaza de profesor en la Universitat Oberta de Catalunya (UOC). En esta universidad he impartido docencia en asignaturas relacionadas con el procesamiento del lenguaje natural y las tecnologías de la traducción, tanto en grados como en másteres. Actualmente, además, dirijo el Máster en Traducción y Tecnologías.
¿Puedes darnos más detalles del proyecto MTUOC de la Universitat Oberta de Catalunya, de sus objetivos y de la filosofía que lo sustenta?
Sé que el nombre no es demasiado original, ya que simplemente combina MT (de traducción automática en inglés) con UOC (de Universitat Oberta de Catalunya).
A. O.: Tanto mi área principal de investigación como de docencia es la traducción automática. Para mis necesidades de investigación en entrenamiento de motores de traducción automática, empecé a desarrollar una serie de herramientas que me facilitaban las tareas de entrenamiento y evaluación. Además, en mis asignaturas sobre traducción automática quería dar un enfoque muy práctico y que los estudiantes pudiesen entrenar y evaluar sus propios sistemas, tanto estadísticos como neuronales. Todas estas actividades me llevaban a mejorar y ampliar las herramientas que desarrollaba. En este punto, ya solo quedaba pendiente el tema de la integración de los motores entrenados en herramientas de traducción asistida, lo que me llevó a desarrollar un programa servidor que es capaz de poner en marcha y conectarse con diferentes motores estadísticos y neuronales. Bauticé a este servidor como MTUOC-server y a todo el proyecto de desarrollo como MTUOC. Sé que el nombre no es demasiado original, ya que simplemente combina MT (de traducción automática en inglés) con UOC (de Universitat Oberta de Catalunya).
¿Qué te llevó a desarrollar el proyecto MTUOC dentro de ese contexto y cuál es tu visión para él?
A. O.: Una vez bien integradas las primeras versiones de las diferentes herramientas del proyecto, empezó a surgir el interés de diversas empresas, lo que llevó a establecer los primeros contratos de transferencia de tecnología. Con estos contratos se cerró el círculo de las actividades que tenemos asignadas los docentes en la universidad: docencia, investigación y transferencia de tecnología. Estos contratos de transferencia han dado un buen impulso al proyecto y permiten desarrollar mejoras continuas en todos los componentes.
Para las personas que no conocen el proyecto MTUOC, ¿cuáles dirías que son sus puntos más fuertes y cómo pueden los traductores aprovecharlos al máximo?
A. O.: Los puntos fuertes del proyecto MTUOC, a mi entender, son los siguientes:
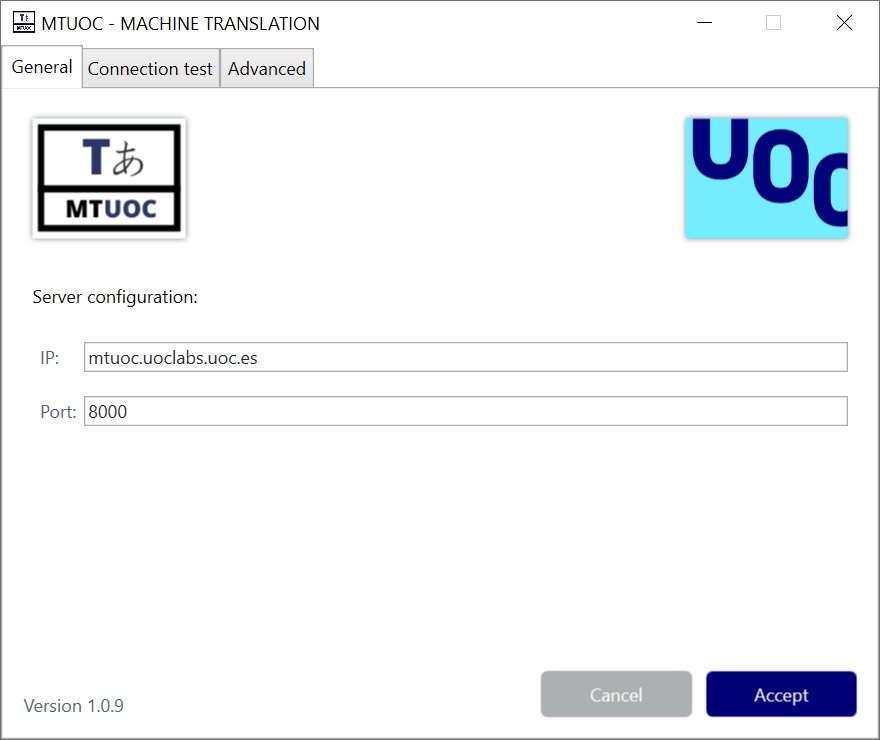
1) El proyecto MTUOC proporciona todas las herramientas necesarias para entrenar, poner en marcha e integrar motores de traducción automática neuronales. Esto incluye algoritmos para crear corpus, alinearlos, limpiarlos y preprocesarlos, entrenar los sistemas y evaluarlos. Además, proporciona un servidor muy versátil que permite conectar los motores entrenados con diversas herramientas de traducción asistida. Además, el servidor incorpora diversos protocolos de comunicación: el propio protocolo MTUOC y además el Moses, OpenNMT, NTMWizard y ModernMT. De esta manera, por ejemplo, podemos poner en marcha un motor neuronal que utilice Marian, pero que actúe como un servidor Moses. Así, nuestros motores serán compatibles con todas las herramientas que incorporen el protocolo Moses.
2) El proyecto, además, distribuye motores ya entrenados para diversos pares de lenguas y especialidades que se pueden descargar y utilizar libremente. La última versión del servidor MTUOC permite, además, utilizar los miles de motores disponibles generados por otros proyectos, como OpusNMT, NLLB y los motores de Softcatalà. Si alguien prefiere utilizar motores comerciales, el servidor MTUOC puede conectarse con Google Translate y DeepL, siempre que se disponga de las credenciales para la API de pago. Así, todos estos motores pasan a ser compatibles con muchas herramientas de traducción asistida, como OmegaT, Trados Studio, Wordfast y las herramientas de Okapi, por citar algunas.
Todos los componentes del proyecto MTUOC se distribuyen bajo una licencia libre (GNU-GPL).
3) Todos los componentes del proyecto MTUOC se distribuyen bajo una licencia libre (GNU-GPL). Esto es muy importante, ya que además de poder utilizar todas estas herramientas de forma gratuita, también se puede modificar el código para adaptarlas a tus propias necesidades. Todas las herramientas están desarrolladas en Python, con un código muy claro y fácil de modificar.
4) El proyecto está bien documentado y se acompaña con materiales docentes y tutoriales. Además, todos estos materiales se distribuyen también con licencias libres, lo que permite utilizarlos y modificarlos.
5) El servidor de traducción se puede poner en marcha tanto en servidores físicos como en virtuales, así como en ordenadores personales y portátiles. No necesita grandes requisitos técnicos, ya que los motores neuronales pueden funcionar incluso sin GPU. Se necesita un entorno Linux, o bien una máquina virtual o el Subsistema de Windows para Linux (WSL).
Para sacar el máximo provecho del proyecto MTUOC, los traductores tienen que atreverse a probar MTUOC en su ordenador con cualquiera de los motores libres disponibles.
¿Qué reacción ha generado el proyecto MTUOC dentro del sector? ¿Ha habido solicitudes de nuevas funciones concretas? ¿Tienes intención de ampliar la colección de herramientas y, si es así, qué piensas hacer?
La UOC puede establecer convenios de colaboración con empresas e instituciones para entrenar motores personalizados a un precio muy competitivo.
A. O.: El proyecto MTUOC ha tenido buena acogida en diversas empresas que han generado sus propios motores. En este sentido, la UOC puede establecer convenios de colaboración con empresas e instituciones para entrenar motores personalizados a un precio muy competitivo. Este servicio de entrenamiento es gratuito para las ONG. Estas empresas necesitan, a veces, personalizaciones de los motores que nosotros podemos desarrollar. Algunos ejemplos de desarrollos específicos que ya hemos implementado son:
1) La detección de lengua del segmento a traducir, porque algunos clientes tenían textos que contenían segmentos en dos lenguas y solo se tenía que traducir el que estaba en una lengua determinada.
2) Filtros de entrada que permiten tratar formatos específicos no estándar.
3) La posibilidad de hacer cambios de cadena o mediante expresiones regulares tanto en el texto a traducir como en la traducción resultante. Otra funcionalidad que ha surgido de los convenios de transferencia es la capacidad de recuperar con mucha precisión, en el texto traducido automáticamente, las etiquetas HTML y XML presentes en el texto original.
4) Como desarrollo inminente nos planteamos la implementación de memorias de traducción, de manera que el motor, antes de traducir, verifica si el segmento está en la memoria con una similitud determinada y, si lo está, devuelve este segmento.
Otra necesidad que ha surgido de una de las empresas colaboradoras es la creación de un entorno de posedición avanzado.
Otra necesidad que ha surgido de una de las empresas colaboradoras es la creación de un entorno de posedición avanzado. En este entorno, el poseditor encontrará el texto original y el traducido automáticamente acompañado de una serie de marcas que indicarán los posibles errores o puntos que merecen más atención. Incluso marcará qué segmentos necesitan posedición y qué segmentos probablemente no necesiten posedición. Será una interfaz sencilla, que funcione como aplicación de escritorio y como aplicación web y que ayudará al poseditor a ser más eficiente.
Y como mejora continua del proyecto, estamos siempre atentos a todas las novedades en lo que se refiere a traducción automática neuronal y a la aplicación de grandes modelos de lenguaje generativo en el mundo de la traducción para poder aplicar estas novedades en nuestros programas.
MTUOC-server es compatible con modelos generados por diferentes motores neuronales de código abierto (p. ej. Marian NMT y OpenNMT). Para las personas que no tienen acceso a la tecnología necesaria (GPU) para generar sus propios modelos, ¿cómo pueden aprovechar todo lo que el proyecto MTUOC les puede brindar?
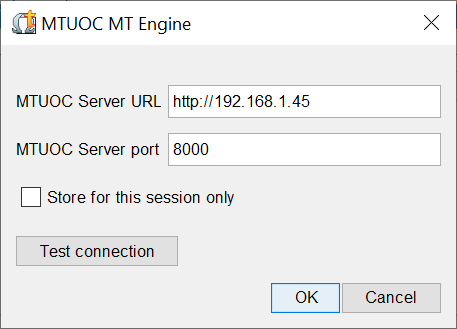
A. O.: Aquí quiero recordar que diversos proyectos ofrecen motores de traducción automática neuronal libres y que son compatibles con MTUOC. Evidentemente, los motores libres que proporcionamos y que se pueden encontrar en la web del proyecto son compatibles con MTUOC-server. Pero, además, se pueden utilizar los más de 1400 motores del proyecto OpusMT (https://huggingface.co/Helsinki-NLP), los modelos multilingües del proyecto NLLB, disponibles para doscientas lenguas. Recientemente, también hemos incorporado los modelos de Softcatalà, que ofrece modelos libres del y hacia el catalán y el alemán, inglés, francés, gallego, italiano, japonés, neerlandés, occitano, portugués y español. Estos modelos se descargan automáticamente cuando se configura el servidor MTUOC. Estoy convencido, además, de que durante los próximos años irán apareciendo nuevos motores de traducción libres que podremos ir incorporando a MTUOC-server. Y en el proyecto MTUOC continuaremos incorporando nuevos pares de lenguas y especialidades y mejorando los que ya tenemos.
Desde tu perspectiva, ¿cómo entiendes la interacción entre los traductores y la traducción automática de aquí en adelante? ¿Qué habilidades van a necesitar los traductores y cómo crees que pueden sacar mayor provecho de esta tecnología?
La menos deseable es la situación en que los traductores van a estar subyugados a la tecnología y van a ser un mero eslabón final de revisión básica y mal pagada.
A. O.: Yo veo dos tipos de interacciones totalmente opuestas que van a convivir al menos durante un tiempo. La menos deseable es la situación en que los traductores van a estar subyugados a la tecnología y van a ser un mero eslabón final de revisión básica y mal pagada. Esto ya está ocurriendo en algunos casos. En esta situación, la tecnología está en manos de unas pocas empresas que imponen las condiciones a los traductores. En este escenario los beneficios de las tecnologías de la traducción recaen sobre un único actor, la gran empresa de traducción, y en todo caso también, de forma más marginal, en el cliente final. El segundo escenario es el inverso, el traductor continúa siendo el protagonista de la tarea de traducción y tiene a su disposición un conjunto de herramientas que le pueden ayudar en su trabajo haciéndolo más efectivo y permitiendo obtener una mejor calidad final. En este escenario, además, el traductor escoge las herramientas que considere que le van a ser más útiles para cada proyecto de traducción. En este contexto, los beneficios de las tecnologías de la traducción se reparten equitativamente entre todos los actores: los traductores, las empresas de servicios de traducción y los clientes finales.
¿Cuál de estos escenarios va a prevalecer? Yo creo que para que prevalezca el segundo escenario se tienen que conseguir dos objetivos:
Las universidades también deberían incluir programas de formación continua sobre tecnologías de la traducción.
1) Que los traductores tengan una formación actualizada sobre las tecnologías de la traducción. Esto se puede conseguir incluyendo estos conocimientos y competencias en los programas universitarios de grado y máster. Las universidades también deberían incluir programas de formación continua sobre tecnologías de la traducción. Pero los traductores también pueden optar por una autoformación continua utilizando los numerosísimos tutoriales existentes en Internet y perdiendo el miedo a probar nuevas herramientas.
2) Que las herramientas tecnológicas sean fácilmente accesibles con opciones de software libre y también comerciales a precios asequibles. Yo sinceramente creo que esta condición ya se cumple actualmente. En lo que respecta a herramientas de traducción asistida, existen opciones de software libre plenamente funcionales, y muchas herramientas comerciales ofrecen precios o suscripciones que son fácilmente amortizables si se utilizan en un entorno profesional. Por lo que respecta a las herramientas de traducción automática, como ya he comentado, existen numerosos proyectos que ofrecen motores libres para muchísimos pares de lenguas y con calidades suficientes para utilizarse en entornos profesionales. Además, los grandes motores comerciales, como podrían ser Google Translate y DeepL, ofrecen accesos mediante API a precios realmente muy bajos y asumibles para cualquier profesional de la traducción. Es cierto que no siempre es fácil integrar todos estos motores en las herramientas de traducción asistida, y en este aspecto nuestro MTUOC-server puede jugar un papel decisivo, ya que facilita la integración de motores propios, libres y comerciales en entornos profesionales de traducción.
Para terminar, ¿qué consejos darías a los traductores que quieren incorporar en su trabajo diario la traducción neuronal con modelos locales y personalizados?
Mi primer consejo sería perder el miedo a probar cosas nuevas. No se va a estropear el ordenador por probar algunas de las herramientas disponibles.
A. O.: Mi primer consejo sería perder el miedo a probar cosas nuevas. No se va a estropear el ordenador por probar algunas de las herramientas disponibles. Una vez perdido el miedo hay que disponer del tiempo necesario para probarlas. En este sentido, creo que hay que estar convencido de que la formación continua es parte de las tareas de un profesional y de que es necesario liberar un cierto tiempo a la semana de la jornada laboral para esta formación. Siempre se puede acudir a los cursos de formación ofrecidos por universidades y empresas, pero la autoformación también es una buena opción. Una buena idea sería dedicarle entre una y dos horas a la semana a probar nuevas herramientas.
En lo que respecta a la traducción automática, una buena opción es utilizar MTUOC, ya que es libre y gratuito, está bien documentado y ofrece materiales docentes y de autoformación, así como diversos tutoriales. Para empezar, recomendaría utilizar los modelos de traducción libres, tanto los de MTUOC como los de otros proyectos que son compatibles con nuestro servidor, especialmente OpusMT, NLLB y Softcatalà. La configuración del servidor MTUOC con estos modelos es automática, ya que simplemente se tiene que indicar qué modelo se desea utilizar y este se descarga automáticamente.
Para entrenar motores propios o hacer fine-tuning de modelos preentrenados, es necesario disponer de unidades GPU potentes.
Para entrenar motores propios o hacer fine-tuning de modelos preentrenados, es necesario disponer de unidades GPU potentes. Afortunadamente, el precio de estas unidades ha bajado considerablemente y es posible comprar ordenadores equipados con una o dos unidades GPU potentes a precios asequibles para profesionales y empresas. También existe la posibilidad de utilizar servidores virtuales equipados con GPU que, para entrenamientos o fine-tunings puntuales, pueden ser una buena opción.
Recordemos que para entrenar motores neuronales es necesario disponer de unidades GPU, pero para traducir con los motores neuronales no es necesario, aunque si disponemos de GPU la traducción también será mucho más rápida. Así, un ordenador equipado con estas unidades puede ser una buena inversión.

Antoni Oliver
Antoni Oliver es profesor agregado de los Estudios de Artes y Humanidades de la Universitat Oberta de Catalunya (UOC, Barcelona, España) y director del Máster en Traducción y Tecnologías. De formación es ingeniero técnico de Telecomunicaciones (UPC), licenciado en Filología Eslava (UB), máster universitario en Software Libre (UOC) y doctor en Lingüística (UB). Sus áreas de docencia e investigación principales son el procesamiento del lenguaje natural, la traducción automática y las herramientas de ayuda a la traducción. Ha participado en diversos proyectos de investigación y transferencia de tecnología y actualmente es el investigador principal del proyecto Traducción automática neuronal para las lenguas románicas de la península ibérica (TAN-IBE). Ha desarrollado numerosas herramientas libres relacionadas con la traducción automática (entre las que destaca el proyecto MTUOC) y la extracción automática de terminología (recogidas en el proyecto TBXTools). Es autor de numerosos artículos en revistas científicas y del libro Herramientas tecnológicas para traductores.