
The article presents the experience with IT-supported quality assurance gathered in the DG Translation of the European Commission. Its main focus is the development of the QA Checker in the Polish Language Department of the DG Translation, the further sharing of this tool with the rest of the departments and finally with other EU institutions. The article describes the main problems related to built-in QA systems and to the development of bespoke systems. It also touches on the development of related tools.
This article is not theoretical. It is experience-based and does not aim at giving any comprehensive view of the current IT-supported quality assurance tools. It focuses on the translation tool currently used in the European Commission (SDL Studio 2017 and previous versions) and on the customisations developed for it.
Why IT-supported quality assurance?
Translating with a CAT tool is a great help to the translator, but it is also a source of new types of mistakes.
While translating, humans make mistakes. Translating with a CAT tool is a great help to the translator, but it is also a source of new types of mistakes. It is easy to overlook tiny differences between the segment to translate and a segment from the translation memory, say the difference between the mathematical symbols ‘<’ and ‘>’. The presence of ‘<’ instead of ‘>’ will have negligible influence on the match value in a longer segment, but confusing these characters constitutes a potentially serious translation error.
As most texts translated in the European Commission are legislative texts, such errors can have serious implications. They can cause disruption in the public administration or cost business operators money and effort. In addition, correcting errors in a published legislative act is both costly and cumbersome. It can only happen via a new legislative act: a corrigendum. Therefore, we do our utmost to avoid translation errors.
However, it is difficult for most humans to detect small differences in source and target, like the difference between ‘<’ and ‘>’. This is where humans can be supported by computers, which – if properly instructed – perform such tasks effortlessly.
Constraints in IT-supported quality assurance
In principle, the previous sentence should allow us to conclude this article. For a skilled person, it is simple to instruct the computer to warn the user of a wrongly applied ‘<’ or ‘>’. Most modern CAT tools have modules which allow users to introduce rules which will produce a warning when for example ‘<’ is found in the source segment, but is missing in the target segment.
The problem is that instructing the computer often gets messy due to the ambiguity and complexity of natural languages or due to stylistic rules used in different text types and languages.
Computers are good at spotting errors, provided the context is unambiguous.
Let us imagine that in some languages the character ‘<’ can be expressed by words in many different ways. The computer, instructed to give the user a warning if ‘<’ is found in the source, but missing in the target, will produce a warning (false positive) for each segment where ‘<’ is rendered – correctly – by words. The rule then needs to be adapted so that the false positives are avoided, but the linguistic variety of the target language will make it complicated to create an appropriate rule.
Even though the example above is artificial, it is based on real life cases. It outlines the main problems for any IT-supported quality assurance system: Computers are good at spotting errors, provided the context is unambiguous. This means that a given text pattern always constitutes an error or that it always constitutes an error when in a given context, i.e. when surrounded by definable text patterns. The problem is that in very few cases a text pattern itself always constitutes an error. Very often, in one context a string is an error, and in another it is not. This means that the computer needs to be fed with more complex rules, which again means more work for the programmer. On the other hand, if the rules are kept simple, false positives are multiplied, thus rendering the IT-supported quality assurance a cumbersome tool for the user for whom finding an error is like finding a needle in a haystack.
The increase of the gravity should lead to increased tolerance for false positives and decreased tolerance for false negatives.
Therefore, when devising QA-rules, it is paramount to achieve a balance between the number of detected real errors, undetected errors (false negatives) and false positives. This balance should depend on the gravity of the error in question: the increase of the gravity should lead to increased tolerance for false positives and decreased tolerance for false negatives.
Studio
As already indicated, making the computer point out possible errors is a standard feature in most CAT tools, also in SDL Studio. Its built-in module contains three sub-modules: QA Checker, Tag Verifier and Terminology Verifier. If active, the modules perform checks on a segment when it is confirmed. The whole document can also be verified (e.g. by pressing F8).
The last of the three modules works only if a term base is attached to the project. The first two have some built-in, predefined checks. In this article, we will focus on the QA Checker which contains most predefined checks, but also some modules allowing user input.
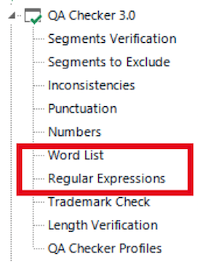
Customisation of Studio
Apart from the built-in rules the QA Checker contains two modules exclusively based on user input: ‘Word List’ and ‘Regular Expressions’ (red box).
In the European Commission, we have discarded most of the built-in checks (contained in the categories ‘Inconsistencies’, ‘Punctuation’, ‘Numbers’, ‘Trademark Check’ and ‘Length Verification’) as too noisy because in many documents they produce hundreds of warnings for few or no errors.
Therefore, we have been working very intensively with the ‘Regular Expressions’ supported by the ‘Word List’ in order to create a more targeted error detection tool. In this article, we will focus on the Regular Expressions-module which offers most possibilities.
What are regular expressions?
Regular expressions […] make it possible to perform pattern-based search or find&replace actions in programs which support them.
Regular expressions are advanced text search patterns. They make it possible to perform pattern-based search or find&replace actions in programs which support them.
A normal search performed by using the Find-function in Studio makes it possible to search for a certain word, e.g. ‘singing’. However, what if we want to find all words starting with an ‘s’ and ending with a ‘g’ in an English original? This is where regular expressions come in handy. For the ‘s…g’-words, the following regular expression would do the job bs[a-z]*gb. More complex strings will require more complex regular expressions. Finding all e-mail addresses would require a longer search string:
\b\w+([\W-[\s]]\w+?){0,3}@(\w+\.){1,3}[a-z]{2,5}\b.
It would be beyond the scope of this article to explain in detail how regular expressions work, but tutorials can be found on the internet. The regular expressions flavour used in Studio is the .NET framework. From the examples shown above, it is apparent that the subject is not intuitive. While it is relatively easy to learn the elements of the regular expressions, mastering their usage can prove to be a challenge.
How is the Quality Assurance Checker used at the European Commission?
In the QA Checker, users can enter regular expression patterns (using the .NET framework) for source and/or target and set a condition for when these patterns are to trigger a message about a possible error (in form of notes, warnings or errors which, unfortunately, are defined globally). The regex pattern(s), together with an appropriate condition and a description, constitute a rule. Rules are saved in a settings file which can be exported and used on other computers. This makes it possible for one person to write rules to be used by others.
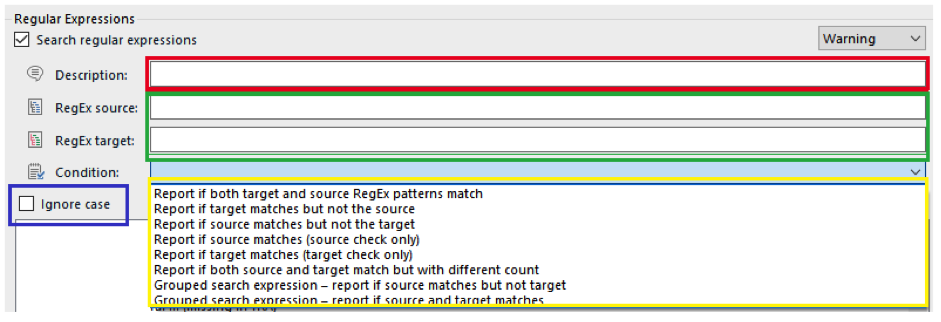
The QA Checker comes empty and needs to be populated with rules by the user. The window where the rules are introduced is shown below (the coloured boxes are added for the sake of this article):
Case study: creating a rule
First steps
Let us imagine that we want to ensure that the word ‘May’ is translated correctly into German as ‘Mai’ (= the 5th month). To this end, we want to create a rule.
First, we need to choose a condition (yellow box above). In this case, we want the program to warn us when ‘May’ is present in source, but ‘Mai’ is absent in target, so the condition ‘Report if source matches but not the target’ would be appropriate. This condition requires two regular expressions (RegExes): one for source and one for target (green box above). We enter them into the appropriate boxes. The regular expressions can be pretty simple1:
RegEx source: \bMay\b
RegEx target: \bMai\b
In the expressions above, the only special characters are \b, which require a word boundary to be present at the given position. When \b precedes and follows a word, the expression will match whole words only. In other words, words like ‘Maybe’ or (oddly spelled) ‘disMay’ will be ignored.
We leave the ‘Ignore case’-box (blue box) unticked as we do not want the system to react to ‘may’, as the name of the month will always start with an uppercase ‘M’ contrary to the verb ‘may’. This will make the system ignore matches like ‘It may be possible…’.
In addition, we need to enter a description of the rule (red box) which will be the warning text displayed to the user each time the rule is activated. A description needs to be short and informative, e.g. ‘May = Mai’ or ‘“May” left untranslated’ so that the user quickly understands the problem. In fact, it is a good idea to number the rules for easy reference. If it is the first rule in a set, the description could be ‘001 May = Mai’.
The rule will look like this:
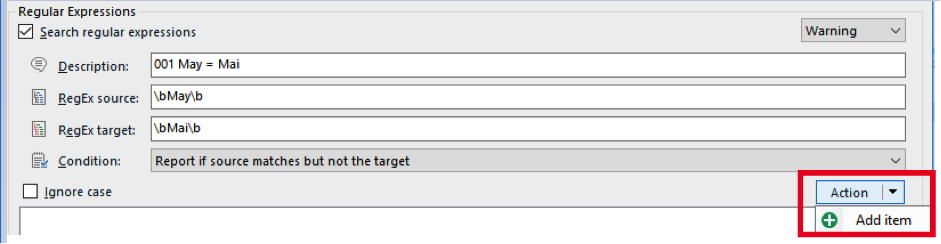
After having been added, one needs to click ‘Action’ and choose ‘Add item’ to add the rule to the set2.
Discovering complexity
While this might seem pretty straightforward, a rule created with the above simple regular expressions will cause many false positives. For example, the RegEx source will create them in the following strings:
- (May be sold)
- Mrs May said…
- Jolly fish (May only be fished in Skagerrak)
- May contain collectively up to 1 % methanol, ethanol and propan-2-ol, on an anhydrous basis.
- May be reduced to accommodate position of floor plates.
To avoid this, one might be tempted to make the regular expression very targeted, e.g. by requiring that a number precedes or follows the word ‘May’. This would mean that the match would only happen in contexts like:
- 15th May
- May the 15th
- May 15th
However, this approach would cause false negatives. For example, the following mistranslations would stay undetected:
- From May to April
- In this period (May to June)
- In May only
A rule which does not detect mistakes is suboptimal. Rules should be balanced – silent, but effective.
A rule which does not detect mistakes is suboptimal. Rules should be balanced – silent, but effective. However, to create a balanced rule, it is necessary to perform a proper linguistic analysis. Based on its results, the context needs to be defined and transformed into regular expressions. This often leads to fairly complicated constructions. Before we can embark on investigating them, we need to have a look at the tools used during linguistic analysis and regex compilation.
Tools
For context analysis, it is reasonable to use a text corpus. To compile the regular expressions, it is necessary to use a regex tester. Regex testers are online tools or stand-alone applications which allow the user to see what a given regular expression captures in a given text.
In addition, it is good practice to construct a test file for each rule containing examples of use divided into two categories:
- Desired matches (see above examples 6-13 with the word ‘May’ in green)
- Undesired matches (see above examples 1-5 with the word ‘May’ in red)
In a regex tester3, the text file (sentences 1-13) would look like this (matches are highlighted by the tester itself):
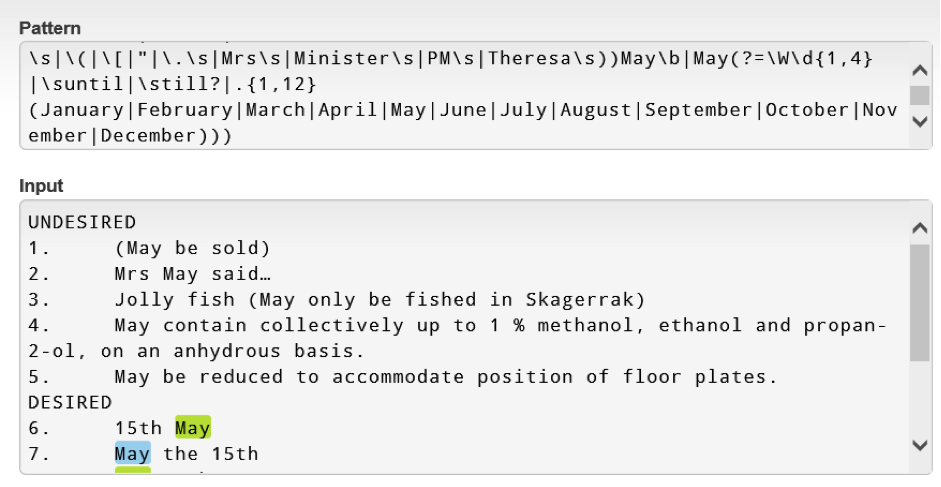
When we introduce changes to the rules, the test file will ensure that the changes have no adverse consequences because as long as the ‘UNDESIRED’ category contains no matches (no highlights) and all sentences in the ‘DESIRED’ category contain at least one match, we know that regular expression performance has not deteriorated. When changing a rule, it is equally important to update the file itself with additional test sentences for each subsequent change of the regular expression.
An additional bonus is that such test file constitutes basic documentation for the given rule.
Linguistic analysis translated into regular expressions
When we have performed the linguistic analysis, we need to transform its results into regular expressions which usually can be done in different ways. Often, the rules are adjusted over time before a satisfactory result is achieved because an expression will need to be corrected many times to strike the right balance between false positives and false negatives.
In the case at hand, the analysis results in dividing the use cases into two main categories:
- The problematic cases where ‘May’ can be a noun or a verb, which is when it appears at the beginning of a new sentence (either a separate segment or a sentence starting after a full stop or inserted in brackets or quotation marks).
- All other cases
Subsequently, these categories need to be transformed into regular expressions. A possible way to do it is presented below. Category I is contained in the blue part of the expression while category II is contained in its red part.
(?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b)|(?<!(^|^\(?\w{1,2}\)?\s|\(|\[|"|\.\s|Mrs\s|Minister\s|PM\s|Theresa\s))May\b
To most readers, this regular expression will probably look quite complicated. Therefore, in the following, a short explanation is offered (without going into regex technicalities which would be too complex).
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | A. The blue part of the expression reacts to ‘May’ if it is preceded: |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 1. directly by a segment start; or |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 2. indirectly by a segment start followed by strings like ‘(aa)’ or ‘1’ |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 3. by the characters ( [ « |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May\b(?!\s(only|not|be|also|[a-z]{5,}|I|(?i)you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 4. or by a dot+space, unless preceded by ‘Mrs’ |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May(?!\s(I|(?i)only|not|be|also|[a-z]{5,}|you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | B. and if ‘May’ is not followed by a space followed by |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May(?!\s(I|(?i)only|not|be|also|[a-z]{5,}|you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 5. any of these words: ‘I, only, not, be, also, you, he, she, it, its, we, they, my, your, his, her, our, your, this’ where everything but ‘I’ is case insensitive |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May(?!\s(I|(?i)only|not|be|also|[a-z]{5,}|you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 6. or any word consisting of at least five Latin letters (case insensitive) |
| (?<=(^|^\(?\w{1,2}\)?\s|\(|\[|"|(?<!Mrs)\.\s))May(?!\s(I|(?i)only|not|be|also|[a-z]{5,}|you|s?he|its?|we|they|my|your|his|her|our|your|the(?!\s\d)|this(?-i))\b) | 7. or the word ‘the’ (case insensitive) if not followed by a digit (to allow strings like ‘May the 5th’) |
Similar considerations are applied to the second part, but they will not be explained in detail here.
| (?<!(^|^\(?\w{1,2}\)?\s|\(|\[|"|\.\s|Mrs\s|Minister\s|PM\s|Theresa\s))May\b | C. The red part reacts to ‘May’ if it is not preceded: |
| (?<!(^|^\(?\w{1,2}\)?\s|\(|\[|"|\.\s|Mrs\s|Minister\s|PM\s|Theresa\s))May\b | 8. by contexts contained in points 1-4 above; by excluding these contexts, everything else is allowed which means all instances where ‘May’ appears within a sentence |
| (?<!(^|^\(?\w{1,2}\)?\s|\(|\[|"|\.\s|Mrs\s|Minister\s|PM\s|Theresa\s))May\b | 9. by the words (all followed by a space): ‘Mrs’, ‘Minister’, ‘PM’, ‘Theresa’ – in other words, ‘May’ within a sentence will not be matched if preceded by these words. |
The above regular expression is a simplified version of the source regular expression used in DG Translation. Needless to say, equal care needs to be applied to the compiling of the target language RegEx.
Language pairs and text types
Up to the 2019-version, it has not been possible to apply the QA Checker to specific language pairs. As reducing the ambiguity has to be language-specific, this has been a serious constraint4. Luckily, in the European Commission, most source texts are written in English. For organisations with varying source languages, the situation would be much more complex.
It is a prerequisite for any IT-supported quality assurance system that the patterns are definable and repetitive.
Another convenient circumstance is the fact that most of the texts translated in the Commission are legislation, which means that we encounter certain similarities in the text patterns. It is a prerequisite for any IT-supported quality assurance system that the patterns are definable and repetitive.
Description of the work done
The QA Checker project started back in 2014 in the Polish Language Department of the DG Translation. A set of English-Polish rules was developed by the author of this article and shared with other departments.
Then a central project was launched under the auspices of a user group for language applications (the EuraCAT User Group, which forms part of the IT governance system in the DG Translation). In the framework of this project, the remaining language departments adapted the Polish rules. To this end, the managers of the language departments were offered the possibility to designate one or two translators to participate in the project. These translators were then trained in compiling regular expressions and asked to adapt the Polish rules to their respective languages. During the process of adaptation, they were assisted (mainly by the author of this article).
The fact that the project has been fully user-driven has been a challenge, but it has given good results. It has been the users (translators) who – knowing the linguistic context and the translation problems – defined/adapted the rules for the QA Checker. Combining the linguistic and stylistic knowledge with IT competences has proved successful. Currently, in the Commission we have 21 functioning rule sets with English as the source language. The only official languages not covered are Finnish and Gaelic. A project to cover the latter has started. No rules have been created for English as target language, either.
The regular expressions module of the QA Checker has become a standard tool.
The regular expressions module of the QA Checker has become a standard tool, reducing the cognitive effort for translators and allowing them to focus on the tasks where humans perform better than machines, e.g. semantics, metaphors, anaphors. Specifically, they are also very helpful when evaluating/reviewing FL texts.
The number of rules contained in the sets vary. Currently, the EN-PL set contains over 400 rules. Some other sets contain more rules, some fewer. This variety is caused by the decentralised nature of the project. Even though a core set of rules was adapted for all languages, many rules are created for single languages or language groups.
Since the adaptation, the English-Polish rules were updated and shared with other language communities. In addition, different language communities worked together to create additional rules (e.g. the Slovak and the Czech communities).
The Commission rules were shared with other European institutions in the first half of 2018. The Commission not only shared the rules, but also provided appropriate training for staff members in the other institutions, so that the project could be adjusted to the specific needs of the other institutions.
Additional gains
An important by-product of the project has been a very strong focus on the use of regular expressions in the DG Translation. We now have a large pool of advanced regular expression users and offer – on a regular basis – courses for translators. The courses cover the usage of regular expressions in the Display Filter in Studio which is a great way of making the translation work more coherent and faster.
Problems – other tools
Our feedback has led to some changes in the latest version of Studio 2019.
During our work with the QA Checker, we have learnt its strengths and weaknesses. There are many of both categories. We have tried to convey some of the most serious constraints to SDL Trados. Our feedback has led to some changes in the latest version of Studio 2019 where the grouped search expressions have been developed according with the suggestions of the Commission.
As the QA Checker has not been able to cope with some tasks, a new development emerged, the Ruby Checker: it works essentially with numbers, but performs also some tag checks, which is not possible in the QA Checker. It is still under development, but it is already usable for many language pairs.
Constraints of other verification tools led to further developments. Excel-based tools with the aim of moving the terminology verification from the Terminology Verifier to the QA Checker regular expressions module are a case in point. The tools are used to automatically transform term lists to QA Checker settings files that can be imported into Studio and used for terminology verification. This boosts the performance and reduces the number of false positives drastically.
Conclusion
Translators need computers to help them focus on the parts of the job where the human brain performs better than the machine.
IT-supported quality assurance and other tools supporting translators gain more and more importance due to the pressure to make the work more efficient, but also due to the usage of other tools, such as machine translation. Navigating in the more and more complex translation environment creates cognitive challenges and translators need computers to help them focus on the parts of the job where the human brain performs better than the machine. From my conversations with different stakeholders in the translation industry I gather that IT-supported quality assurance will gain more and more importance in the coming years, and rightly so, as it seems to have been a neglected area for many years.
1 Some readers might wonder here why it is worthwhile to check month names since they are often autosubstituted in Studio. While autosubstitution works for month names within a long date, it does not in other occurrences. And a mistake in a month name constitutes a serious translation mistake. This is why constructing such rules makes sense.
2 As it is quite cumbersome to add and change rules in Studio itself, and as it is very impractical to e.g. change the order of the rules, in the DG Translation we use an Excel tool developed by the Czech Language Department making it possible to import/export QA Checker settings into/from Excel.
3 Here the tester RegexStorm was used due to the temporary unavailability of a better performing tool, RegexHero, on EC computers.
4 It is, in fact, striking how few errors are language-independent. Things like numbers, abbreviations, brackets, punctuation are all language-specific either linguistically or because of stylistic requirements.

Grzegorz Okoniewski
Grzegorz joined the European Commission in 2011 as translator. Gradually, his focus moved to IT. He is now language technology coordinator and master trainer. He was the primary motor for the development of customized quality assurance checks in DG Translation. Before joining the Commission, Grzegorz worked in the educational sector (university and secondary school) and as a lexicographer. He is the author of the Danish-Polish Legal Dictionary (Copenhagen 1999, 946 p.).
