
A menudo nos fijamos en aquellas soluciones terminológicas que dan los alumnos que comienzan a traducir textos especializados cuando, en realidad, no saben cuál es el equivalente en la lengua materna por no estar especializados en el campo sobre el que habla el texto. En este estudio se pretende observar las pautas, los métodos y los pasos que siguen los alumnos para encontrar aquel equivalente que creen correcto para la traducción.
Introducción
En este artículo describo los resultados de un estudio cuantitativo que llevé a cabo en 2012, como tesina de licenciatura, sobre un conjunto de fichas de correspondencia léxica (inglés-español) elaboradas por alumnos de traducción especializada de la Universidad Pontificia Comillas en el curso 2011-2012.
El proyecto de investigación se centró en tres disciplinas: traductología, terminología y documentación. Mi objetivo principal era identificar los mayores problemas en los procedimientos de búsqueda léxica empleados por los estudiantes de Traducción e Interpretación, para definir algún tipo de protocolo sistemático que ayude a estudiantes y profesionales tanto en la búsqueda como en la selección de terminología de campos especializados.
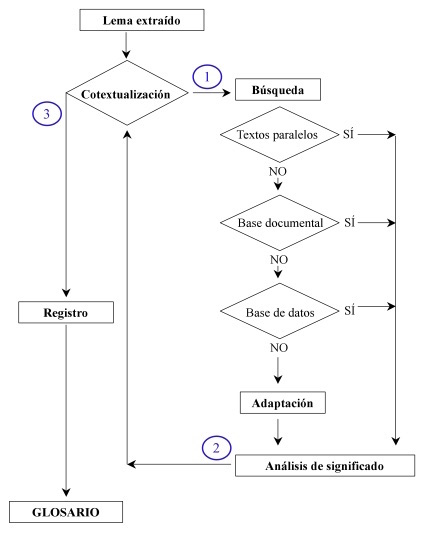
Conviene puntualizar que este estudio se plantea tomando como base un artículo publicado en 2011 por las profesoras Mª Luisa Romana y Pilar Úcar (2011), quienes propusieron a la sazón el siguiente diagrama de flujos, que podría servir como modelo procedimental para la búsqueda y selección de terminología especializada.
Gracias a esta propuesta, tanto alumnos como traductores profesionales pueden seguir una serie de pasos sistematizados para buscar la terminología adecuada del campo sobre el que estén traduciendo; es decir, en un contexto determinado.
En el estudio me planteé poner a prueba la viabilidad y utilidad de ese diagrama y, además, jerarquizar los grupos de fuentes propuestas por Romana y Úcar (2011).
Un abismo entre la palabra y el término
En un principio partí de un problema que, en mi opinión, mostraban los alumnos de Traducción e Interpretación a la hora de llevar a cabo las búsquedas terminológicas cuando traducían un texto especializado. Me di cuenta de que los estudiantes no poseían los procedimientos terminológicos necesarios para traducir correctamente. Fue entonces cuando me surgió la duda de «cómo se enseña a buscar y a elegir la terminología adecuada».
Hasta ese momento, yo no tenía noticia de otros protocolos propuestos que ofrecieran unos pasos sistematizados para buscar terminología. Esta propuesta resultaba muy práctica y útil si se podía corroborar que de verdad funcionaba.
Todo buen traductor sabe que necesita una serie de herramientas para traducir y, a lo largo del aprendizaje de este arte, se va dando cuenta de que los diccionarios ayudan a conseguir este objetivo, pero no son lo único que debe utilizar.
Seguramente hayan escuchado en boca de terceros célebres frases como «¿traducir? muy fácil, con un buen diccionario…»; «¿y no crees que en un futuro serán las máquinas quienes traduzcan?, con lo rápido que está mejorando Google Translate…» o «yo alguna vez también he hecho algún trabajillo de traducción; con un buen diccionario bilingüe está chupao».
Según Cabré (1999b), los términos se deben estudiar in vivo, es decir, es necesario analizar su manera de actuar y de aparecer en su hábitat natural: los textos especializados.
Es muy fácil tomar un diccionario y comenzar a traducir. El problema llega cuando el traductor no posee la suficiente información para determinar cuál es el léxico adecuado en un campo específico.
Palabra y término son conceptos distintos, hecho que podemos apreciar a la hora de distinguir entre lenguaje general y lenguaje especializado. La primera diferencia que existe entre ambos conceptos es el tipo de textos en el que aparecen. Las unidades terminológicas, que pertenecen al lenguaje especializado —y por lo tanto encontraremos en textos especializados—, presentan unas características específicas (ya sea el texto, que será especializado, el destinatario, que resultará ser experto en una materia, o el uso del término en sí, que estará bastante limitado al campo al que pertenezca).
Por ello, Cabré (1999b) define el término como aquella palabra asociada a una gran información semántica, sintáctica y pragmática; así, el término tendrá un valor determinado en función de su contexto y su uso.
De modo que sí, es necesario tener en cuenta algo más que un equivalente del término en un diccionario. Necesitamos determinar el contexto del término que deseamos traducir. De esta manera, podremos ver cómo actúa tanto en la lengua origen como en la lengua meta y, así, podremos encontrar la denominación más apropiada en el idioma de destino.
Las fuentes documentales
Romana y Úcar (2011: 314) jerarquizan las fuentes empleadas atendiendo a su grado de relación con la materia: «Se trata de una codificación ordinal que asigna a priori la pertinencia, atendiendo a la fiabilidad que cabe esperar intuitivamente, desde el punto de vista de un traductor, a cada uno de los recursos». Sin embargo, para mi estudio, el procedimiento no fue el mismo; en este experimento no se jerarquizaron las fuentes documentales, ya que son variables nominales. Esto me supuso un problema metodológico y debería corregirse en caso de continuar en un futuro con este estudio.
En cuanto a las conclusiones de Romana y Úcar (2011: 321), «[…] la mayor correlación se aprecia entre la aceptabilidad y la referencia, que parece por tanto el factor más importante en una búsqueda adecuada. Interpretamos la primera correlación como un posible indicador de la fiabilidad de cada clase de fuente. Por orden descendente, resultará mejor la búsqueda en a) textos paralelos (referencia exactamente correspondiente), b) bases documentales (referencia globalmente correspondiente) y c) bases de datos (todas las referencias posibles)». Esta observación queda plenamente confirmada en el estudio que aquí presento, donde el orden propuesto de las fuentes documentales es el mismo que resulta del estudio de las correlaciones.
Organización del experimento, paso a paso
Con respecto al procedimiento del estudio descrito en este artículo, se llevaron a cabo los pasos descritos por Romana y Úcar para poder realizar con éxito un experimento que ofreciese resultados relevantes respecto a las fuentes documentales utilizadas por un traductor a la hora de traducir un texto especializado: cotextualización, búsqueda, análisis de significado y verificación de registro.1
- Cotextualización
En esta etapa, se compilaron una serie representativa de cotextos del texto original en los que apareciera el lema buscado. Al utilizar textos procedentes de instituciones europeas relevantes en el mundo de la traducción, podíamos conseguir su traducción (propuesta por la institución) al español. - Búsqueda
Se efectuó la búsqueda de los lemas procedentes del texto original en los tipos de fuentes documentales:- Textos bilingües
- Bases documentales
- Bases de datos (terminológicas y lexicográficas).
- Análisis de significado
Se verificó si la correspondencia obtenida significaba lo mismo que el lema en los documentos traducidos por la misma institución emisora de los originales. - Verificación de registro
Una vez obtenida una propuesta (o varias) de traducción, era necesario proceder a la denominada «verificación de registro» (vr): la comprobación del uso real de la expresión en el campo especializado. Para ello, se procedió a una nueva búsqueda de las unidades castellanas halladas, y los resultados se ordenaron atendiendo a los siguientes criterios:- Fuentes especializadas
- Frecuencias de uso dentro de ellas
La etapa de vr se realizó con un buscador general en Internet (Google), introduciendo el lema encontrado entre comillas, y se anotaron los datos necesarios para la verificación de registro.
Descripción del experimento
Para poder estudiar lo propuesto, llevé a cabo un experimento con estudiantes de tercer curso de Traducción e Interpretación. Diseñé un calendario con una serie de sesiones en las que los alumnos debían recopilar cierta información a la hora de llevar a cabo la búsqueda terminológica en textos del campo de la macroeconomía. De este modo, los alumnos fueron anotando en unas fichas previamente diseñadas por mí distintos datos sobre sus búsquedas, tales como si habían encontrado la correspondencia en español del término en inglés, las fuentes que habían utilizado para encontrar el equivalente, información sobre la verificación de registro (la cantidad y la fiabilidad) y observaciones de interés a la hora de realizar las búsquedas.
La información proporcionada me serviría más adelante para determinar el grupo de fuentes más fiable a la hora de traducir y aquellos puntos en los que un traductor debería prestar más atención para no caer en una mala traducción.
Respecto a los grupos de fuentes documentales sobre los que trabajaría, decidí recoger varias páginas web que consideré podrían ser útiles y las incluí dentro de uno de los tres tipos de fuentes nombrados anteriormente.
A continuación se muestra la ficha sobre la que trabajaron los estudiantes, con la información que les pedía y una breve explicación de algunos de los campos más importantes (para poder entender mejor las conclusiones que saqué al final del estudio):
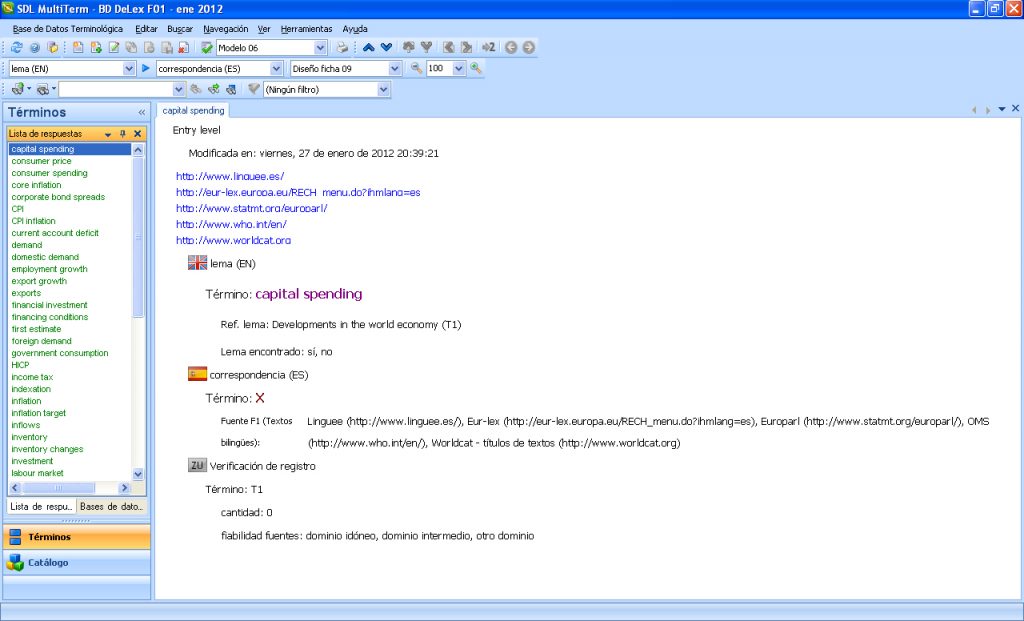
Campos de las búsquedas terminológicas
- Referencia del lema: un campo en forma de lista (picklist)2. De esta forma, los estudiantes se encontraron con una lista que conforma los distintos textos con los que se llevarían a cabo las búsquedas terminológicas.
- Comentarios: para que los alumnos pudieran escribir, en forma de nota, advertencias o incidentes.
- Autor: el nombre de alumno.
- Fuente: también se definió en forma de picklist. En ella, los sujetos eligieron aquellas fuentes donde pudieron encontrar el equivalente en español del término en inglés (dentro del grupo de fuentes que se les había asignado; por ejemplo, si el grupo tenía encargado buscar el término en las fuentes de textos bilingües, dentro de la picklist encontrarían EUR-Lex, Europarl, Worldcat, etc.).
- Lema encontrado: se configuró también en forma de picklist y en ella los alumnos tan solo pudieron responder «sí» o «no» en función de si habían encontrado un equivalente satisfactorio (desde su punto de vista) en español; cabía la posibilidad de que, dentro del plazo de tiempo definido para realizar la búsqueda de términos, los alumnos no pudieran dar con el equivalente.
- Verificación de registro: dentro de este campo encontramos dos subcampos:
- Cantidad: es el número de entradas encontradas en el registro; para verificar si el término encontrado se suele utilizar en el campo económico, se practicó una prueba de resultados en Google; los estudiantes recogieron en este campo el número de entradas que aparecían al introducir ese equivalente léxico en el motor de búsqueda. Esto es útil si, por ejemplo, tras realizar una búsqueda con las distintas fuentes documentales, observaban que tenían dos equivalentes léxicos en español de una misma entrada. Para comprobar cuál está más acuñado o se utiliza más, podían realizar búsquedas booleanas en Google y ver cuál de los dos arrojaba más resultados.
- Fiabilidad de las fuentes: es una picklist en la que se responde en función de lo fiables que han sido las fuentes en las que han encontrado el término equivalente en español. En esta picklist se pueden elegir las siguientes opciones:
- Dominio exacto
- Dominio intermedio
- Otro dominio
Decidí organizar toda esta información en bases de datos y codificarla. Como se puede observar, muchos de los campos ofrecen información no cuantitativa sino nominal (como la fiabilidad de las fuentes); para poder estudiar todo con claridad, es necesario que cada información tenga un valor numérico. Así, cuando hablamos de cantidades, la variable es escalar (numérica) y, si se trata de un concepto, nominal (por ejemplo, término buscado o correspondencia castellana encontrada). La tercera posibilidad es la de las variables ordinales, que presentan una jerarquización; sería el caso del tipo de fuente. Se presentan estos valores en forma de cuadro:
| VARIABLE | TIPO DE VARIABLE |
|---|---|
| Lema [EN] | Nominal |
| Texto original | Nominal |
| Autor | Nominal |
| Tipo de fuente | Ordinal |
| Lema encontrado (s/n) | Ordinal |
| Correspondencia [ES] | Nominal |
| Cantidad | Escalar |
Otros datos de búsqueda
Además de los datos proporcionados por los alumnos, en cada ficha se añadieron los tres datos siguientes:
- Traducción buscada: término utilizado en la traducción profesional del to, el texto oficial publicado. Variable nominal.
- Precisión del resultado (con arreglo a la vr): distancia entre la correspondencia propuesta por el alumno y la versión encontrada en la vr. Se ordenó de la siguiente manera: 0 = totalmente distinto; 1 = parcialmente distinto; 2 = exactamente igual. Variable ordinal.
- Nota de traducción: calificación asignada por la profesora. Variable escalar.
Análisis de los resultados
Con toda la información recogida, organizada y codificada, comencé el análisis y estudio del experimento y extraje los resultados más relevantes.
Según la Real Academia de la Lengua Española, una correlación es la medida de la dependencia que existe entre variables aleatorias. Se obtuvo el siguiente cuadro de correlaciones:
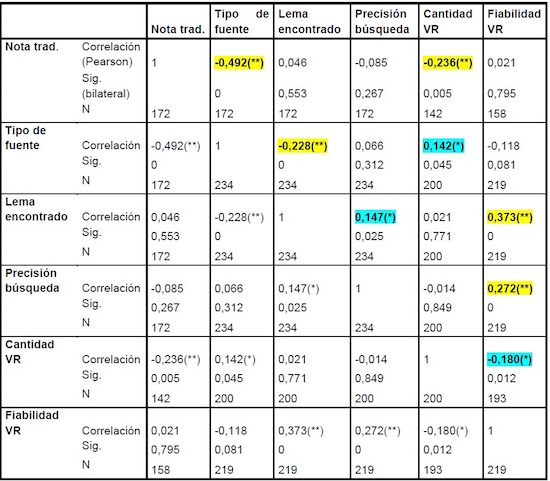
Pasamos ahora a comentar estos resultados. En primer lugar se observa que el tipo de fuente está muy relacionado con la nota de la traducción (corr = –0,492 / p = 0,000), es decir, en términos generales, a fuentes más especializadas, mayor calidad del texto meta. El signo negativo nos confirma que la calidad del tm está efectivamente relacionada con el tipo de fuente y, además, con el orden de fuentes documentales que se preveía en la hipótesis (respecto a la fiabilidad en el uso para la traducción especializada): los textos cuya terminología se buscó en textos bilingües obtuvieron mejor nota que los buscados en bases documentales, y estos mejor a su vez que los buscados en bases de datos. Por otra parte, la calidad del texto también estuvo asociada con la cantidad obtenida en la vr (corr = –0,236 / p = 0,005), lo que demuestra la utilidad de este método.
También observamos una relación no casual entre el tipo de fuente y el hecho de haber encontrado o no el lema (corr = 0,228 / p = 0,000). Será pues más probable encontrar unidades terminológicas en bases textuales, de tipo EUR‑Lex, DTSearch o memorias de traducción ad hoc.
Dentro de los datos correspondientes a la vr, hay que señalar que el dato de fiabilidad está relacionado con la precisión de la búsqueda (corr = 0,272 / p = 0,000), lo que refuerza la calidad del protocolo documental que estamos examinando, en este caso con respecto al segundo criterio de verificación de registro, la fiabilidad de las fuentes. No obstante, hay que decir que lo sorprendente hubiera sido no encontrar correlación, puesto que es de puro sentido común que, a mejores fuentes, mejores resultados. El procedimiento queda adicionalmente confirmado por la relación hallada entre los dos subcomponentes de la vr, cantidad y fiabilidad (corr = 0,180 / p = 0,012); no obstante, atendiendo a la baja correlación, podemos también interpretarlo en el sentido de que indica el elevado nivel de especialización de los términos seleccionados. La cantidad de vr, por su parte, aparece relacionada también con el tipo de fuente, con la correlación más pequeña de toda la serie (corr = 0,142 / p = 0,045). Es a la vez uno de los resultados más informativos: cuanto más especializada sea la fuente, menor será la cantidad de ocurrencias en Internet. Nuevamente vemos en esto un indicador de especialización tecnolectal. No obstante, para extraer conclusiones definitivas necesitaríamos conocer además el dato del equilibrio o desequilibrio entre el número de fuentes de los tres tipos. Por último, la correlación hallada entre la fiabilidad de la vr y el hecho de haber encontrado el término buscado (corr = 0,373 / p = 0,000) indica asimismo que, si encontramos el lema en alguna fuente, independientemente de la calidad, será más probable obtener una vr más segura: el procedimiento —bastante habitual en los traductores avezados— de buscar directamente una posible formulación en castellano, sin pasar por la búsqueda bilingüe, mejorará mucho si nos esforzamos por encontrar primero el lema en inglés.
Conclusiones
En vista de los resultados de este estudio de verificación de la propuesta de Romana y Úcar (2011), cabe en primer lugar recomendar la inserción de un nuevo elemento en el esquema general: se trata de un filtro, un procedimiento que podría denominarse «adecuación de la correspondencia» que haría que, en algún momento previo a la verificación de registro, fuera posible confirmar que la traducción hallada recoge toda la información presente en el lema.
De esta forma, si decidimos llevar a cabo una búsqueda del término «capital gain tax», para empezar, deberemos tener en cuenta que dentro de esta unidad terminológica existe otra que es capital gain y que puede conllevar un cambio en cuanto al concepto principal. Tras una búsqueda en Google, observamos que nos da un resultado de 428 000 páginas (una cantidad bastante alta), y que aparecen como principales resultados los gobiernos del Reino Unido, Australia y Estados Unidos. Nos centramos en el concepto dentro del área de la macroeconomía y analizamos el significado del término y su uso, es decir, su contexto. A continuación, nos movemos por las fuentes del primer grupo que estudiamos, esto es, las fuentes documentales (Linguee, EUR-Lex…) y observamos que obtenemos varios resultados para el mismo término. Vemos que para «impuesto sobre el incremento de capital», Google nos ofrece 9 resultados; para «impuesto sobre ganancias de capital», obtenemos 12 200 resultados; para «impuesto sobre plusvalía», nos encontramos con 59 200 páginas web; y para «impuesto de plusvalía», 125 000 resultados. Podemos afirmar que las dos últimas opciones serán las más fiables a la hora de traducir capital gain tax. Además, si observamos el tipo de resultados que nos ofrece Google respecto a «impuesto de plusvalía», observamos que obtenemos páginas de gobiernos, ayuntamientos, bancos, etc., lo que corrobora la fiabilidad de la traducción.
No obstante, como inciso, me gustaría apuntar que, al realizar la verificación de registro con Google, me encontré con el problema de que, actualmente, este buscador no siempre respeta el uso de comillas para delimitar las búsquedas. Para poder conseguir este efecto en búsquedas a la hora de comprobar esta información, recomiendo utilizar un buscador denominado Exalead. Con esta herramienta, el traductor puede realizar búsquedas aplicando diversos filtros para delimitar todavía más los resultados obtenidos. De este modo, es posible añadir filtros una vez obtenidos los resultados (a la izquierda aparecen las opciones de idioma, términos relacionados, tipo de páginas web, categoría o año). Asimismo, es posible realizar una búsqueda inicial avanzada, lo que nos da la posibilidad de añadir operadores booleanos para delimitar las búsquedas (palabras o frases exactas, términos opcionales, orden de las palabras en una frase o expresión, aproximadores, proximidad…), indicar si queremos obtener resultados publicados en Internet hasta o desde una fecha, etc. Este buscador lleva operando en España desde 2007 y cuenta con un índice de más de 8 millones de páginas.
En resumen, podemos avanzar las siguientes conclusiones prácticas del estudio:
- La traducción será mejor si se buscan los términos por el siguiente orden de fuentes:
- Bases textuales bilingües (EUR-Lex, DTSearch, memorias de traducción)
- Bases documentales (corpus, páginas web monolingües)
- Bases de datos (IATE, glosarios y elencos terminográficos bilingües)
Además, desde el punto de vista estrictamente terminológico, será más probable encontrar una buena solución respetando este orden de búsqueda.
- La traducción será mejor si los términos meta encontrados se someten a verificación de registro o vr: una búsqueda monolingüe en Internet, tras la que se anotará la cantidad de resultados obtenidos y la fiabilidad media de las fuentes.
- Por último, cuanto más especializado sea un texto, menos cantidad de resultados obtendremos en Internet para sus términos, lo que nos obliga a prestar aún más atención al tipo de fuente.
En el caso de no conseguir resolver la fiabilidad de la traducción a través de la tecnología, es necesario que sea el traductor quien recurra a alguna fuente personal que le ayude a decidir si se puede o no seguir este método de traducción al pasar de unidades simples a compuestas, ya sea porque cambie el sentido de la idea o simplemente porque no se utilice en el campo especializado.
En cualquier caso, podemos afirmar que queda demostrado que existe una jerarquización a la hora de elegir qué fuentes son más fiables en el contexto de la traducción de textos sobre macroeconomía. Este avance puede ayudar tanto a los traductores actuales en el ejercicio de su profesión como a los estudiantes de Traducción e Interpretación que todavía estén aprendiendo y adquiriendo las habilidades lingüísticas y conceptuales necesarias para convertirse en traductores profesionales que sepan realizar búsquedas documentales de gran valor para su oficio. Aun así, es necesario continuar investigando en el terreno de la búsqueda documental y terminológica con el fin de continuar aportando información relevante para la profesión traductora y traductológica.
Bibliografía
Alcaraz Varó, E. El inglés profesional y académico. Madrid: Alianza, 2000.
Bessé, B. de. «Terminological Definitions». En: Basic Aspects of Terminology Management, 1997, p. 63-74.
Cabré, M. T. «Hacia una teoría comunicativa de la terminología: Aspectos metodológicos». Revista Argentina de Lingüística, (1999a).
Cabré, M. T. La terminología: Representación y comunicación: Elementos para una teoría de base comunicativa y otros artículos. Barcelona: Universitat Pompeu Fabra. Institut Universitari de Lingüística Aplicada, 1999b.
Cabré, M. T. La terminología: Teoría, metodología, aplicaciones. Barcelona: Antártida/Empúries, 1993.
Estopà, R. «Eficiencia en la extracción automática de terminología». Perspectives: Studies in Translatology [Copenhague], (1999), p. 277-286.
Lorente, M. y Bevilacqua, C. «Los verbos en las aplicaciones terminográficas». En: Actas del VII Simposio Iberoamericano de Terminología RITerm 2000. Lisboa: ILTEC, 2000.
Microsoft Office. «Video: Crear un gráfico en Excel». En: Soporte Online [recurso electrónico]. [última consulta: 09/04/2012].
Monteros, H. Estadística descriptiva Excel 2007: Excel para mejorar la productividad [vídeo]. [última consulta: 09/04/2012].
Pérez Hernández, C. Explotación de los corpora textuales informatizados para la creación de bases de datos terminológicas basadas en el conocimiento, Tesis Doctoral. Málaga: Universidad de Málaga, 2000.
Romana, M. L. y Úcar, P. «“Al final dejé esto”: las decisiones léxicas en traducción». Revista de Lingüística y Lenguas Aplicadas [Valencia], volumen 6 (2011). [última consulta: 28/03/14].
Romana, M. L. La sintaxis en la traducción económica (inglés-español) [Tesis Doctoral]. Madrid: Universidad Pontificia de Comillas, 2009.
Sager, J. C. y Somers, H. Terminology, LSP, and Translation: Studies in Language Engineering in Honour of Juan C. Sager. Ámsterdam: J. Benjamins Pub. Co., 1996.
Sager, J. C. Curso práctico sobre el procesamiento de la terminología. Madrid: Fundación Germán Sánchez Ruipérez, 1993.
Sinclair, J. M. «The Empty Lexicon». International Journal of Corpus Linguistics (1996).
Subirats, R. C. Introducción a la sintaxis léxica del español. Madrid: Iberoamericana, 2001.
Wüster, E. The Road to Infoterm: Two Reports Prepared on behalf of Unesco: Inventory of Sources of Scientific and Technical Terminology: A Plan for establishing an International Information Centre (Clearinghouse) for Terminology. Pullach bei München: Verlag Dokumentation, 1974
1 Por razones de espacio, no me es posible desarrollar plenamente los pasos del
2 Picklist es una forma de caracterizar el campo que se está diseñando, que se basa en poner una lista de resultados u opciones para que, a la hora de rellenar la ficha de una entrada, en ese campo se pueda responder marcando una de las opciones escritas (previamente). En Multiterm es posible indicar si queremos que en ese campo sea posible escribir como tal (como por ejemplo en «Comentarios») o elegir una de las opciones que propone el campo (como por ejemplo en «Lema»), entre otras cosas.

Blanca H. Pardo
Blanca H. Pardo es estudiante de doctorado en Traducción Médica. Trabaja como traductora autónoma EN/FR>ES y es gestora de proyectos en Blink Translations. Se licenció en Traducción e Interpretación por la Universidad Pontificia Comillas y tiene un máster de especialización en Traducción Médico-Sanitaria por la Universitat Jaume I.
