
Welcome on board! No es la primera vez que en Asetrad nos preguntamos si la revolución tecnológica traerá de la mano una simplificación sintáctico-léxica de la lengua. Como muestra, un botón: La lengua que no cesa. En la entrevista a la que remito, dialogan dos perfiles lingüísticos con posiciones bastante alejadas. Aun así, cuando se les pregunta por esta posible (mala) influencia, ambas están bastante de acuerdo: la máquina será la que tendrá que aprender a comunicarse mejor gracias a la sofisticación de los sistemas digitales.
En este artículo os cuento un viaje. En concreto, el mío: he cruzado océanos de tiempo para explicaros todo lo que he encontrado en mi periplo por la corrección en los mundos digitales y la interacción humano-máquina. ¿Cómo una máquina aprende a hablar una lengua?, ¿se la puede corregir?, ¿cómo? Yo más bien diría que se trabaja con ella, pero veremos que este paseo es bastante cartesiano y está lleno de dudas (que para algo somos correctores) e interferencias entre campos del conocimiento, en principio, muy diferentes entre sí. Pero ¿qué son la transformación y la cultura digitales sino un jaque a las fronteras y estructuras preestablecidas? Absténganse, pues, fieles de la cuadratura del círculo y creyentes acérrimos del cajonismo estanco.
Cross-check OK
Las asetraderas que me acompañaron el pasado 28 de octubre en la celebración del Día Internacional de la Corrección 2019 en nuestra sede me hicieron la primera pregunta (bastante ochentera, por cierto): ¿Qué hace una chica como tú, licenciada en Filología, en un sitio como este, lleno de datos y tecnología? Pues la vida, ¡qué voy a deciros!, y muchas horas de picar tecla: la llegada de proyectos cada vez más relacionados con la inteligencia artificial (IA) hizo que fuera desprendiéndome poco a poco, aunque no del todo, del sector académico, mi punto de origen. Por ello, desde 2017 compagino proyectos editoriales y tecnológicos. Nada mal si te gustan los retos y dormir poco, y tu gusanillo de la curiosidad se ha comido al pepitogrillo de los autónomos.
¿En qué ha consistido mi colaboración en estos proyectos? Básicamente, en trabajar con los famosos small o big data procesados por la máquina.
¿En qué ha consistido mi colaboración en estos proyectos? Básicamente, en trabajar con los famosos small o big data procesados por la máquina (mejor dicho, por los algoritmos preparados por los programadores para que la máquina se coma, en este caso, las cadenas de habla y las convierta en cadenas de texto analizable). Esto es, tras las fases de entrenamiento propias del procesamiento de lenguaje natural (PNL)1, se comprueba su calidad lingüística y se validan o no antes de pasar al siguiente nivel: presentar conclusiones, soluciones o posibles mejoras para el software o algún punto concreto del proceso. Pero empecemos por el principio de los tiempos. Quizá se vea más claro con algunos ejemplos lingüísticos mi casilla de salida en estos andurriales.
¿Qué hacemos con las catalanadas/castellanadas, por ejemplo, en casos como «¿A qué hora plegues?» o «Et truco en un rato»?
Cuando empecé con estas colaboraciones lingüístico-técnicas, me encargaba de solventar errores de puntuación y ortografía (especificar la puntuación o no, pues se ha de saber cómo interpreta la máquina una pausa o diferenciar ciertos pares problemáticos como que/qué, si/sí, sino/si no, etc.), así como de léxico, atendiendo especialmente localismos, comprobación de nombres propios y ambigüedades debidas a la falta de contexto (o a la falta de conocimiento pragmático de la máquina). Esto es especialmente divertido, pues entran en juego los conocimientos lingüísticos y el poder de interpretación para resolver problemas como los siguientes: ¿Qué ocurre con proyectos en los que participan territorios diglósicos? ¿Qué hacemos con las catalanadas/castellanadas, por ejemplo, en casos como «¿A qué hora plegues2?» o «Et truco en un rato»?, ¿cómo las reconoce la máquina? ¿El usuario se llamará Anna o Ana? Como en posedición, existe la regla tácita de los tres segundos: las decisiones han de ser rápidas y consecuentes con el libro de estilo debido a la ingente cantidad de material que hay que tratar.
Como veis, lo que hacemos cada día: trabajar el texto según las necesidades o indicaciones del cliente.
Cabin crew prepared for take-off
Si alguno de vosotros ya ha metido un poco la nariz en este campo, no se extrañará si digo que nuestro trabajo no acaba aquí. Es decir, siempre que hablamos de datos, hablamos de contenido. Y donde hay contenido, estamos nosotros. La gran diferencia es el equipo: ya no estamos solos en nuestro despacho, cruzando correos con traductores, editores o autores. Aquí se trabaja mano a mano con lingüistas computacionales, localizadores, matemáticos, estadistas e ingenieros de telecomunicación, entre otros perfiles técnicos, como uno de relativo nuevo cuño: el científico de datos.
¿Qué pasa si mezclas estadística y literatura? La respuesta, muy lejos del «la he liao parda», es algo tan maravilloso como la lectura distante.
Por ello y poco a poco, fui interesándome por labores no relacionadas, en principio, con las de una corrección más tradicional. Gracias a la estilometría y el entorno RStudio, para el lenguaje de programación R, empecé a cogerle el puntillo a la estadística y a la visualización de datos, pero, sobre todo, al cruce de campos: ¿qué pasa si mezclas estadística y literatura? La respuesta, muy lejos del «la he liao parda», es algo tan maravilloso como la lectura distante.3 ¡BOOM!
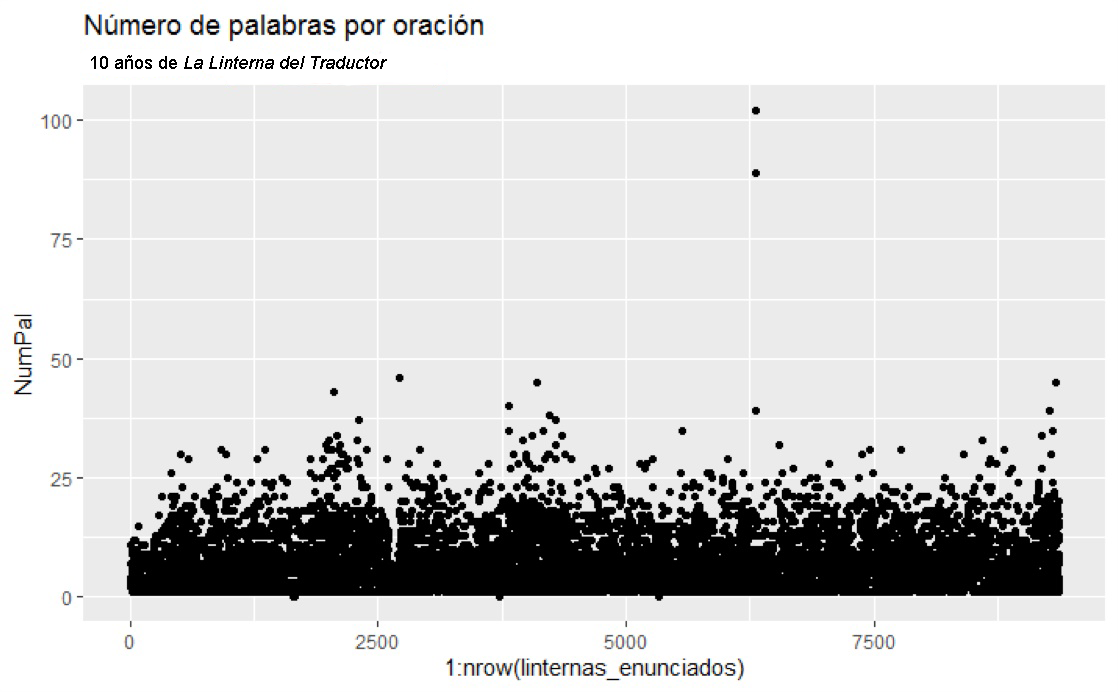
La estilometría no es otra cosa que analizar el texto (grandes cantidades de texto) a través de ciertos valores escogidos, ayudándote de la estadística, y comprobar si el resultado nos dice algo relevante, por ejemplo, de un género literario o un autor. Esto encaja a la perfección con dicha modalidad de lectura propuesta por Franco Moretti.4 Vemos ahora un experimento hecho en casa. Hemos cogido los números de los diez años de La Linterna del Traductor (formato html) y los hemos limpiado, esto es, hemos eliminado las llamadas palabras gramaticales o de función, que suelen ser las más comunes.5 Con una base de datos ya limpita, obtenemos que estos diez años de la publicación se han edificado sobre más de 9000 oraciones, cuya longitud media ronda entre 10 y 20 palabras, aunque ha habido un par de ejemplos (valores atípicos) que rondan el centenar.
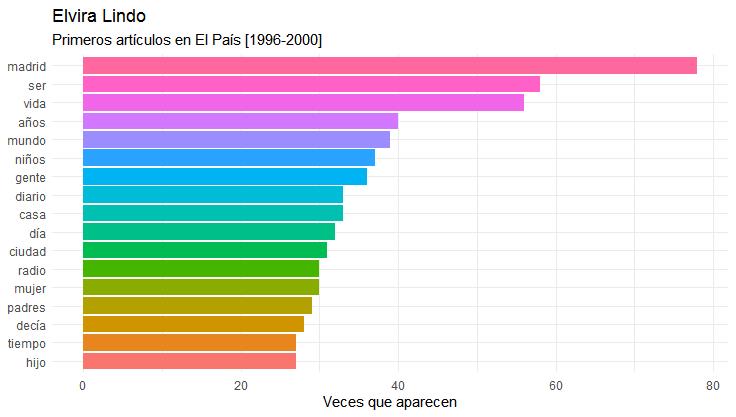
La siguiente imagen nos muestra otro ejemplo de todo lo que es capaz de hacer la estilometría. En ella se ven las palabras más frecuentes en los primeros artículos de Elvira Lindo en El País. Si se hiciera una comparativa entre, por ejemplo, sus cien primeros textos y sus cien últimos, seguro que las palabras cambiarían. Esto nos daría pie a preguntarnos, por ejemplo, si se debe a un cambio de interés temático de la autora. También podríamos analizar ambos grupos de palabras por separado o en conjunto según el contexto sociocultural y político de cada momento, si este cambio de palabras-temas tiene relación o se apoya en otras obras publicadas por la autora en ese periodo, etc.
Have a nice flight!
Según mi experiencia, la formación híbrida es fundamental. Estamos muy lejos de aquella separación bizantina entre ciencias y letras.
Todo esto está muy bien, pero ¿qué necesita un corrector 360 para trabajar con máquinas? Según mi experiencia, la formación híbrida es fundamental. Estamos muy lejos de aquella separación bizantina entre ciencias y letras. Por ello, el ámbito de la lingüística computacional es el mejor para acercarse a este campo: hay que entender la computación, saber qué datos necesitas y cómo dárselos a la máquina para que ella sepa qué hacer. No son uno ni dos los compañeros con gran experiencia en programación y docencia a sus espaldas quienes me han asegurado que la curva de aprendizaje en computación es mucho más rápida en gente con perfil lingüístico que en el caso contrario. Pero aquí nos encontramos con un gran palo en la rueda (o, por seguir con el símil, en el motor del avión): esta división de ámbitos del conocimiento sigue estando fuertemente asentada, por lo que los filólogos, humanistas, traductores, etc. lo tenemos algo complicado a la hora de ponernos manos a la obra con la formación técnica (matemáticas, estadística, lenguajes de programación o consultas estructuradas para bases de datos, etc.). Sin contar honrosas excepciones, como el apoyo a la investigación del Grupo de Ingeniería Lingüística (UNAM) o diferentes másteres como el de Tecnologías de la Información o Lingüística Computacional (UNED y UPF) o Lenguas y Tecnología (UPV), entre otros, la formación híbrida sigue siendo escasa y cara, pues sin duda hay numerosas academias en las que se imparten talleres intensivos (o bootcamps) en los que iniciarse en el desarrollo de webs, diseño UX, análisis de datos, programación, etc. A esto se le añade la preferencia de la que disfrutan los perfiles técnicos durante los procesos de admisión a escuelas y academias. Y, por si no fuera suficiente, casi todo el corpus está en inglés. Aquí podríamos abrir un gran melón: la necesidad de crear contenido digital de alto nivel tecnológico e inteligencia artificial en español. Pero lo dejaremos para el postre.
Además de la formación, es preciso contar con ciertas habilidades técnicas: manejar lenguajes de programación o de etiquetado/de consultas estructuradas (SQL); saber trabajar con editores de código, programas de visualización de dato y gestores de contenido; tener cierta idea de estadística (sobre todo, si se va a trabajar con Machine Learning, análisis de datos y toma de decisiones) tampoco está de más. Sé que puede parecer apabullante. De hecho, lo es: hay una miríada de opciones, pero ¿nadie se acuerda ya de ese momento crítico en el que, ¡oh, misterio!, nos pidieron por primera vez corregir en InCopy, en InDesign, en PDF o en código? ¿Te acuerdas de la primera vez que saltaste de Word a WordFast, a OmegaT, ¡incluso a Dragon!?, ¿y del día en que te dijiste «bueno, va» y cambiaste el Excel por Trados? Pues esto igual. ¡Ojo! En ningún momento digo que sea obligatorio este cambio de herramientas o de hábitos profesionales, solo apunto un camino, unas nuevas salidas profesionales que creo que se abren para nosotros. Desde investigación y docencia hasta los perfiles dos-en-uno (técnico-lingüísticos) de los que hablábamos arriba, pasando por los novedosos botmaster o el analista de datos lingüísticos, quien sabrá aplicar la sintaxis, la gramática y la ortografía según corresponda, pero que también será capaz (porque se habrá formado para ello) de programar, extraer, tratar, almacenar, analizar e incluso visualizar datos. Para ello, lo único (lo único) que hemos de hacer es aprender, una vez más, un idioma o, en este caso, un lenguaje nuevo. Quien quiera entender…
This is your captain speaking…
Durante mis colaboraciones como analista de datos lingüísticos en empresas que, en principio, nada tienen que ver con el gremio, he observado unos cuantos rasgos que se repiten y que pueden llegar a ser definitorios.
Aunque es cierto que las nuevas profesiones tecnológicas disfrutan de cierta flexibilidad horaria y trabajo en remoto, el grueso del proyecto suele llevarse a cabo desde las oficinas del cliente-jefe.
El primero es el trabajo en plantilla. Aunque es cierto que las nuevas profesiones tecnológicas disfrutan de cierta flexibilidad horaria y trabajo en remoto, el grueso del proyecto suele llevarse a cabo desde las oficinas del cliente-jefe. Esto se debe a la naturaleza sensible del material con el que se trabaja: los datos. Seguridad, privacidad y confidencialidad es su máxima… al menos, en principio. Desde las redes sociales hasta los sistemas de recomendación de contenidos o los smart speakers, ¿qué pasa con los usos éticos de estos sistemas digitales? Otro gran melón, sin duda.
Los perfiles híbridos están de suerte: actualmente, hay más demanda que oferta, por lo que están bien remunerados y gozan de libertad para desarrollar herramientas y métodos de trabajo con el fin de encontrar aquello que mejor se ajuste a las necesidades de la empresa, del producto o del proyecto. Eso sí, son muchas horas de curro picando tecla (algo de lo que ya sabemos, ¿verdad?). No fear here!
No se entiende que la segunda lengua más hablada en el mundo, con 580 millones de hispanohablantes, sea la sexta en contenido científico, la cuarta en contenido digital y la novena en plataformas como Wikipedia.
Pásame el cuchillito y te sirvo una ración: retomo el melón idiomático de la escasa infraestructura tecnológica en español. No se entiende que la segunda lengua más hablada en el mundo, con 580 millones de hispanohablantes,6 sea la sexta en contenido científico, la cuarta en contenido digital y la novena en plataformas como Wikipedia. Respuesta a esta necesidad de crear una IA y sus consecuentes productos digitales en español es el proyecto LEIA de la Real Academia con Fundación Telefónica, Google, Microsoft, Amazon y Facebook, empresas autodenominadas como datacéntricas. No obstante, no está exenta de polémica: no son pocas voces, especialmente de compañeros americanos, las que señalan esta cesión de datos como un acto globalitario en las antípodas de los esfuerzos realizados en pro de la ciencia abierta o la localización de los datos. Además, expresiones como «unificar el español frente a la influencia inglesa» se han tildado de colonialismo digital. ¿Unificar el español?, ¿eliminar localismos y sesgos? Precisamente, uno de los trabajos de los lingüistas computacionales es entrenar a la máquina con el lenguaje normativo y, a la vez, con sesgos lingüísticos para que esta entienda cada vez a más hablantes y la interacción sea cada vez menos rígida. Por otro lado, ¿qué variedad será la unificadora?, ¿vuelve el fantasma del español neutro a recorrer un mundo globalizado? Colegas EN > ES, aquí hay tomate. Solo digo eso…
Sin una buena estrategia detrás, la inteligencia artificial es más injusta con la sociedad, más exclusiva.
Más allá de LEIA y Luke Skywalker, está la Comisión Europea, la cual instó a sus Estados miembros a publicar su respectiva estrategia nacional antes de julio de 2019. Pero, un momento… ¿alguien ha visto por algún lado la nuestra? Efectivamente, está sin publicar. Se estima que la inversión europea en I+D destinada a IA puede ser de más de 20 000 millones de euros, así que eso que nos estamos perdiendo. Además, deberíamos tener en cuenta lo que apunta Nuria Oliver en su discurso de ingreso7 en la Real Academia de Ingeniería (cuya lectura es un deleite). Los datos son la causa de esta cuarta Revolución Industrial cuyos sistemas alcanzan e impactan en la vida de millones de personas; sin una buena estrategia detrás, la inteligencia artificial es más injusta con la sociedad, más exclusiva.
Cabin crew prepared for… landing?
De momento, la inteligencia artificial es inteligencia humana y, por tanto, nunca es neutral ni está libre de valores.
Quedan en el aire algunas cuestiones que no creo posible resolver ni aquí ni ahora, aunque, sin duda, acabaremos volviendo a ellas. Apenas hemos hablado de los usos éticos de la IA, de la censura de contenido en redes sociales, de la detección de noticias falsas ni del periodismo aumentado. Dejémoslo en que, de momento, la inteligencia artificial es inteligencia humana y, por tanto, nunca es neutral ni está libre de valores; la IA contiene una serie de vicios o sesgos nada difíciles de ver si se lee bien la entrelínea de ciertas empresas.8 No obstante, supone un continuo viaje de ida y vuelta en el que todos tenemos cabida porque todos acabaremos en él, colaborando o fagocitados, eso depende de la posición de cada uno. En mi opinión, no hay más que apostar por la formación necesaria o quedaremos irremediablemente obsoletos. Quizá el error haya sido temerla en lugar de enfrentarla, quedarnos con la anécdota y no extraer la chicha: preocuparnos más por qué consecuencias (siempre negativas, por supuesto) iba a tener en nuestro trabajo dentro de la cueva correcto-traductoril y no en qué nos iba a ayudar, en cómo podíamos aliarnos con ella para trabajar juntos.
La transformación y la cultura digitales no son un proyecto, sino un proceso de evolución continua y constante. El futuro ya está aquí, el futuro era esto (parafraseando a Radio Futura y Marinetti). Todos tenemos cabida en él. Todos somos datos. ¿O qué te habías pensado tú, humano?
Bibliografía
Del Río Riande, Gimena. «Humanidades digitales bajo la lupa: investigación abierta y evaluación científica». Exlibris. 2018.
Instituto Cervantes. «El español, una lengua que hablan 580 millones de personas, 483 millones de ellos nativos». [Consulta: 04/02/2020].
Fradejas, José Manuel. «Estilometría, análisis de textos en R para filólogos». Cuentapalabras. [Consulta: 07/02/2020].
Moretti, Franco. Distant Reading. Nueva York: Verso, 2013.
Oliver Ramírez, Nuria M. «Inteligencia Artificial: Ficción, realidad y… sueños». Madrid: Real Academia de Ingeniería. [Consulta: 04/02/2020].
«Plegar». Diccionari.cat. [Consulta: 04/02/2020].
Schweighauser, Phillip. «What is distant reading?». Future Learn. [Consulta: 04/02/2020].
1 Producción de lenguaje natural y comprensión de lenguaje natural (también NLG y NLU, respectivamente, por sus iniciales en inglés).
2 Plegar [s. xiii; del ll. plicare, íd., der. de plectĕre, plexum ‘entrellaçar’], en su segunda acepción, momento en el que se acaba la jornada de trabajo diaria.
3 Los atrevidos podéis encontrar aquí más información sobre esta manera de acercarse al texto y empezar a tirar del hilo: What is distant reading? (Schweighauser).
4 Moretti, 2013.
5 En lingüística forense o en el análisis para la atribución de autoría de un texto, este tipo de palabras, conocidas en informática como palabras vacías (stopwords, para los anglófilos), no se descartan, ya que a través de ellas podemos obtener conceptos reveladores. Si queréis saber más sobre esto, no dejéis de consultar el magnífico curso de Estilometría con R para filólogos, del profesor José Manuel Fradejas (Universidad de Valladolid).
6 Instituto Cervantes, 2019.
7 Oliver Ramírez, 2018.
8 Dos ejemplos de esto vienen de la mano de Lorena Jaume, quien creó The Ethical Tech Society y el Algorithm Watch para controlar que las GAFAM ejecuten sus algoritmos sin sesgos.

Judith de Diego
Judit(h) de Diego (Segovia, 1987) es licenciada en Filología Románica y Literatura Comparada, y máster en Tecnologías de la Información para la Sociedad Digital y Data Science. En 2013 creó su asesoría lingüística; desde entonces, gestiona proyectos y equipos. Especializada en edición literaria y académica, también se la puede ver por los andurriales de la docencia (ELE y literatura española en diferentes programas universitarios), la transcripción y la posedición de programas de reconocimiento de voz y el análisis de datos para empresas culturales. Hija de una estanquera y un albañil, tiene dos gatos y es pizzapiñera.
